I feel like there is an interesting connection between this and the FFT operation we learned int CS 170. In that case, we were attempting to do a convolution operation (computing the product of two polynomials in coefficient space) and to do so -- we evaluate the polynomials at various points and multiply -- then interpolate to recover the original polynomial.
patrickrz
I'm wondering if there needs to be any correlation between the surface area of the filter and the original size of the cartoon image. In this case, if there picture of the girl was larger in terms of surface area, would the black and white filter also need to scale in terms of surface area?
jonathanlu31
Along those lines, how does image resolution affect the frequency domain? Or rather what does sampling the image look like in the frequency domain?
austinapatel
Theoretically, is it faster to perform the Fourier transform on both the image and the filter and then multiply in the frequency domain and then do the inv fourier transform back or to just do the convolution operator in the pixel space? I'm curious to know what methods GPUs and CPUs have to make these respective operations faster.
Staffjamesfong1
@austinapatel Great question. In big-O notation, the improvement of switching to the frequency domain first is O(N2)→O(NlogN). This is due to a beautiful algorithm known as the Fast Fourier Transform. In addition, specialized algorithms exist to take advantage of GPU power to make FFT's extremely quick in practice. e.g. NVIDIA has an entire library dedicated solely to FFT. And if you don't have a GPU, there exist every efficient CPU implementations as well. This means it is pretty much always better to switch to use the frequency domain.
The only exceptions are when the filter has some special structure that allows for a specialized algorithm. For example, if you know your filter is a box (like on this slide) you can use summed area tables to achieve O(N) speed.
Messier-16
I've taken some math classes that abstract away objects like these so much. I feel like there must be a deep way of understanding why a frequency domain multiplications are the same as convolutions. ex. Are these objects duals of each other?
Also, what happens if you do a Fourier transform of the frequency domain, is that useful?
joeyzhao123
I'm still a little confused on the multiplications and what they mean. I sort of understand the Frequency domain one but I am unsure what the one in the spatial domain represents.
Messier-16
@joeyzhao123 The spatial domain represents a convolution. Basically you take that square (3 by 3 with all 1's) and slide it across the image, taking the average pixel at each window and replacing the image pixels themselves. Naturally you see that blurred version at the end of doing this on every pixel
armaangoel78
@jamesfong1 this was a bit surprising to me because I assumed that CNNs weren't implemented using a forrier transform. Looking into it a bit, this thread (https://www.quora.com/Can-we-apply-CNN-to-frequency-domain) said that its not possible as Relu doesn't work in the forrier domain, but that doesn't make sense to me since you can switch back to spatial before doing ReLu.
This one (https://towardsdatascience.com/how-fourier-transform-speeds-up-training-cnns-30bedfdf70f6) said that it fourier transform does speed things up, but now I'm confused why CNN implementations don't do this (or maybe they do and its just under the hood somewhere).
Curious if anyone knows about all of this.
Staffjamesfong1
@armaangoel78 Interesting! I do not know the answer either. If the library authors chose not to use an FFT, I would guess it is because the kernel and image sizes common in machine learning are not large enough to need FFT. Or it could be other special considerations like applying non-linearities as you mention.
Staffmcallisterdavid
@armaangoel78 CNNs typically use very small kernels (3x3 is most common) like James said. These are efficient to run on GPU hardware with highly optimized implementations. Furthermore, you typically perform "channel-mixing" by convolving multiple channels at the same time and mixing their outputs. In practice, you can improve performance and memory consumption dramatically by using something like grouping (https://towardsdatascience.com/grouped-convolutions-convolutions-in-parallel-3b8cc847e851) or kernel decomposition (https://jacobgil.github.io/deeplearning/tensor-decompositions-deep-learning). I'm not sure these features would be easy to implement in the frequency domain.
Like you mentioned, you'd have to do an inverse FFT to apply non-linearities, which would incur two extra O(n^2 * log(n)) operations per layer since you'd want a non-linearity after each. I'd be surprised if you notice a big speedup if you FFT and inv. FFT at each layer.
Convolutional layers in PyTorch aren't even proper convolution--they implement cross correlation (in practice doesn't make a difference because the kernels are learned).
That being said, PyTorch added a differentiable FFT routine (https://twitter.com/PyTorch/status/1369519707028480002) so you could run experiments for yourself!
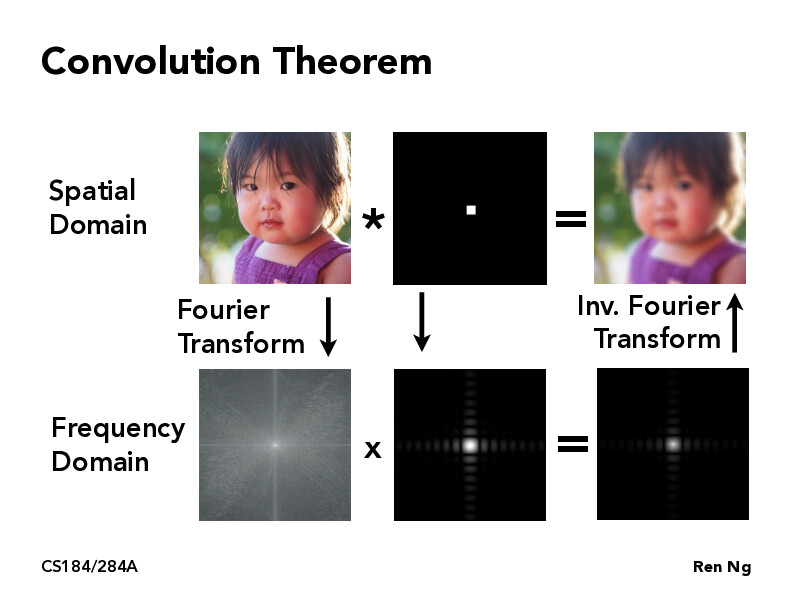
I feel like there is an interesting connection between this and the FFT operation we learned int CS 170. In that case, we were attempting to do a convolution operation (computing the product of two polynomials in coefficient space) and to do so -- we evaluate the polynomials at various points and multiply -- then interpolate to recover the original polynomial.
I'm wondering if there needs to be any correlation between the surface area of the filter and the original size of the cartoon image. In this case, if there picture of the girl was larger in terms of surface area, would the black and white filter also need to scale in terms of surface area?
Along those lines, how does image resolution affect the frequency domain? Or rather what does sampling the image look like in the frequency domain?
Theoretically, is it faster to perform the Fourier transform on both the image and the filter and then multiply in the frequency domain and then do the inv fourier transform back or to just do the convolution operator in the pixel space? I'm curious to know what methods GPUs and CPUs have to make these respective operations faster.
@austinapatel Great question. In big-O notation, the improvement of switching to the frequency domain first is O(N2)→O(NlogN). This is due to a beautiful algorithm known as the Fast Fourier Transform. In addition, specialized algorithms exist to take advantage of GPU power to make FFT's extremely quick in practice. e.g. NVIDIA has an entire library dedicated solely to FFT. And if you don't have a GPU, there exist every efficient CPU implementations as well. This means it is pretty much always better to switch to use the frequency domain.
The only exceptions are when the filter has some special structure that allows for a specialized algorithm. For example, if you know your filter is a box (like on this slide) you can use summed area tables to achieve O(N) speed.
I've taken some math classes that abstract away objects like these so much. I feel like there must be a deep way of understanding why a frequency domain multiplications are the same as convolutions. ex. Are these objects duals of each other?
Also, what happens if you do a Fourier transform of the frequency domain, is that useful?
I'm still a little confused on the multiplications and what they mean. I sort of understand the Frequency domain one but I am unsure what the one in the spatial domain represents.
@joeyzhao123 The spatial domain represents a convolution. Basically you take that square (3 by 3 with all 1's) and slide it across the image, taking the average pixel at each window and replacing the image pixels themselves. Naturally you see that blurred version at the end of doing this on every pixel
@jamesfong1 this was a bit surprising to me because I assumed that CNNs weren't implemented using a forrier transform. Looking into it a bit, this thread (https://www.quora.com/Can-we-apply-CNN-to-frequency-domain) said that its not possible as Relu doesn't work in the forrier domain, but that doesn't make sense to me since you can switch back to spatial before doing ReLu.
This one (https://towardsdatascience.com/how-fourier-transform-speeds-up-training-cnns-30bedfdf70f6) said that it fourier transform does speed things up, but now I'm confused why CNN implementations don't do this (or maybe they do and its just under the hood somewhere).
Curious if anyone knows about all of this.
@armaangoel78 Interesting! I do not know the answer either. If the library authors chose not to use an FFT, I would guess it is because the kernel and image sizes common in machine learning are not large enough to need FFT. Or it could be other special considerations like applying non-linearities as you mention.
@armaangoel78 CNNs typically use very small kernels (3x3 is most common) like James said. These are efficient to run on GPU hardware with highly optimized implementations. Furthermore, you typically perform "channel-mixing" by convolving multiple channels at the same time and mixing their outputs. In practice, you can improve performance and memory consumption dramatically by using something like grouping (https://towardsdatascience.com/grouped-convolutions-convolutions-in-parallel-3b8cc847e851) or kernel decomposition (https://jacobgil.github.io/deeplearning/tensor-decompositions-deep-learning). I'm not sure these features would be easy to implement in the frequency domain.
Like you mentioned, you'd have to do an inverse FFT to apply non-linearities, which would incur two extra O(n^2 * log(n)) operations per layer since you'd want a non-linearity after each. I'd be surprised if you notice a big speedup if you FFT and inv. FFT at each layer.
Convolutional layers in PyTorch aren't even proper convolution--they implement cross correlation (in practice doesn't make a difference because the kernels are learned).
That being said, PyTorch added a differentiable FFT routine (https://twitter.com/PyTorch/status/1369519707028480002) so you could run experiments for yourself!