Lecture 9: Intro to Ray-Tracing & Accelerating Ray-Scene Intersection (89)
keatonfs
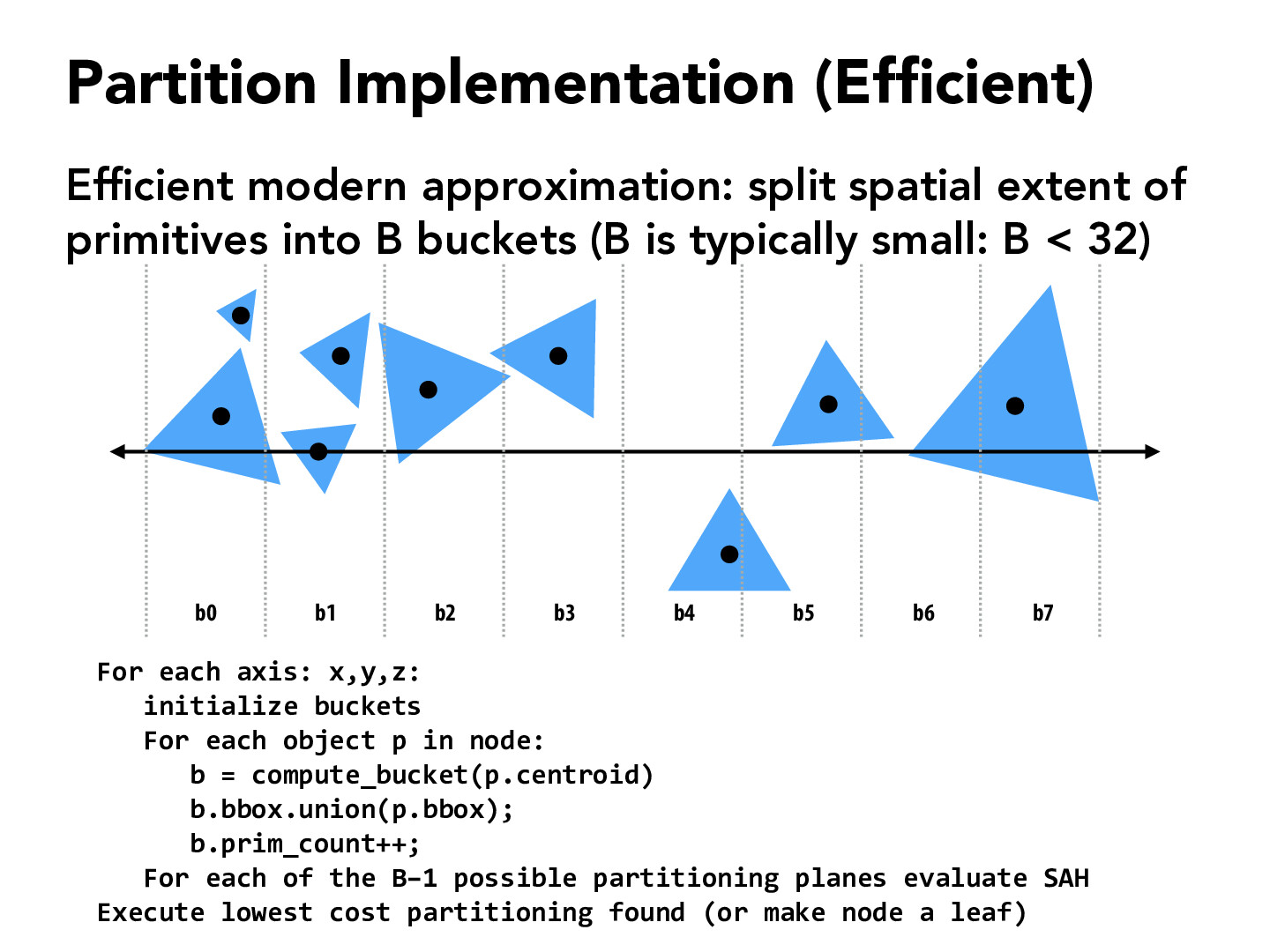
I'm a little confused by this. Are the only possible partitioning planes that we can have buckets? And we then recurse on these buckets?
TinnaLiu
If I understand this correctly, we separate the entire space into B buckets, and the planes that separate each buckets are referred to as the "partitioning planes". For the second part of your question, I think we would run this partition algorithm once at each inner node to decide the next split.
joeyzhao123
This kind of reminds me of minimum spanning trees. I saw the word prim in the algorithm and it seems like the overarching ideas are similar. I wonder if this idea came from prims?
omaryu17
@joeyzhao123, from my understanding, the prim in this algorithm comes from counting the number of primitives in each bucket, whereas the prim in Prim's algorithm comes from the name of one its developers. I can see what you mean by overarching ideas though, as this algorithm executes a lowest cost partitioning, which is similar to the MST algorithm selecting the lowest cost edge found at each step to build its structure.
ShrihanSolo
Can this be optimized further by starting from the mean location and then trying splits around the mean? Once the SAH starts worsening we choose the best bucket and continue.
I'm a little confused by this. Are the only possible partitioning planes that we can have buckets? And we then recurse on these buckets?
If I understand this correctly, we separate the entire space into B buckets, and the planes that separate each buckets are referred to as the "partitioning planes". For the second part of your question, I think we would run this partition algorithm once at each inner node to decide the next split.
This kind of reminds me of minimum spanning trees. I saw the word prim in the algorithm and it seems like the overarching ideas are similar. I wonder if this idea came from prims?
@joeyzhao123, from my understanding, the prim in this algorithm comes from counting the number of primitives in each bucket, whereas the prim in Prim's algorithm comes from the name of one its developers. I can see what you mean by overarching ideas though, as this algorithm executes a lowest cost partitioning, which is similar to the MST algorithm selecting the lowest cost edge found at each step to build its structure.
Can this be optimized further by starting from the mean location and then trying splits around the mean? Once the SAH starts worsening we choose the best bucket and continue.