Here is another really great resource on sampling from a distribution given its PDF: http://prob140.org/textbook/content/Chapter_16/03_Simulation_via_the_CDF.html
This resource gives a more formal proof on the "inversion method" and helps with giving intuition on what's happening. We are effectively using a Uniform(0,1) distribution as a random number generator, then applying the inverse of our CDF to randomly generated values to find the corresponding sample from our distribution of interest
adam2451
In applications, how would we go about integrating the integrals required. I assume this is done numerically. Does this limit the types of things we can model?
SudhanvaKulkarni123
Another method that one can use would be rejection sampling. Inversion sampling can often be hard for algebraically complicated distributions. In such a case, one can use rejection sampling - which is often less efficient but easier to implement. It works on any distribution. One can check the wiki for a more detailed description. But the idea is essentially, we generate a random variable from a reference distribution and return only certain generated samples in order to approximate our target distribution.
zeddybot
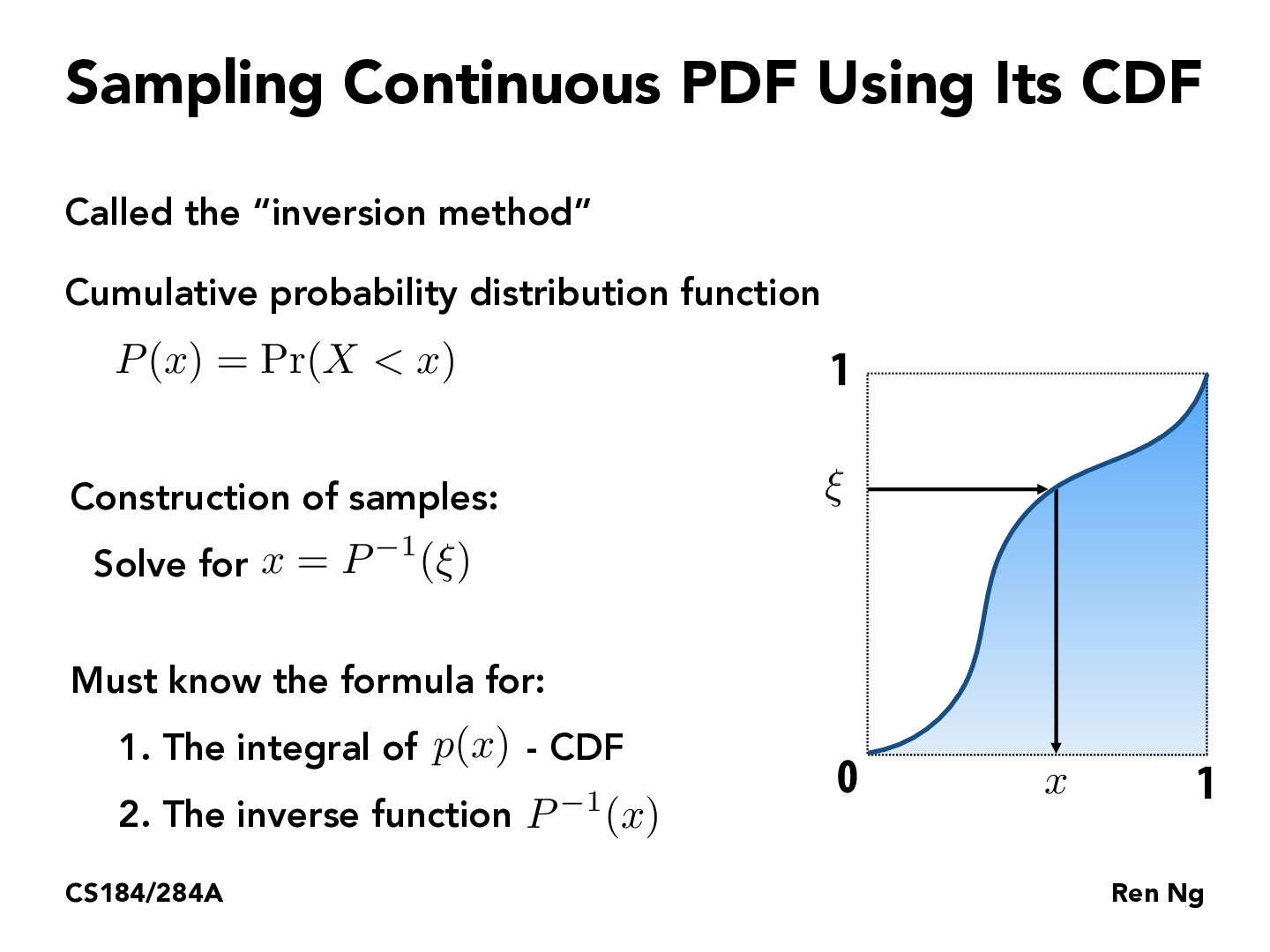
It's cool that since the CDF is always an increasing function, we don't need to compute its inverse necessarily. We can use binary search to find the x value that corresponds to a particular choice of y. You can choose the tolerance on your binary search to tune how much error you allow to come from any given random sample.
stephanie-fu
I can imagine some efficient implementations of this CDF search that cache previously-found values to help with faster retrieval for future values of eta.
Here is another really great resource on sampling from a distribution given its PDF: http://prob140.org/textbook/content/Chapter_16/03_Simulation_via_the_CDF.html
This resource gives a more formal proof on the "inversion method" and helps with giving intuition on what's happening. We are effectively using a Uniform(0,1) distribution as a random number generator, then applying the inverse of our CDF to randomly generated values to find the corresponding sample from our distribution of interest
In applications, how would we go about integrating the integrals required. I assume this is done numerically. Does this limit the types of things we can model?
Another method that one can use would be rejection sampling. Inversion sampling can often be hard for algebraically complicated distributions. In such a case, one can use rejection sampling - which is often less efficient but easier to implement. It works on any distribution. One can check the wiki for a more detailed description. But the idea is essentially, we generate a random variable from a reference distribution and return only certain generated samples in order to approximate our target distribution.
It's cool that since the CDF is always an increasing function, we don't need to compute its inverse necessarily. We can use binary search to find the x value that corresponds to a particular choice of y. You can choose the tolerance on your binary search to tune how much error you allow to come from any given random sample.
I can imagine some efficient implementations of this CDF search that cache previously-found values to help with faster retrieval for future values of eta.