If I am understanding correctly the purpose of this method of using the inverse is basically because it allows us to generalize random sampling. In computers and applications we can randomly generate a value between 0 and 1 which our CFD will lie between and then the inverse will actually allow us to get a sample generated in the pdf that we are concerned with, allowing us to be general with any underlying distribution. While typing this I now came across another question: what if our sampling distribution did not have an inverse, are we out of options or is it not something we have to worry about because the pdfs we choose will have nice properties?
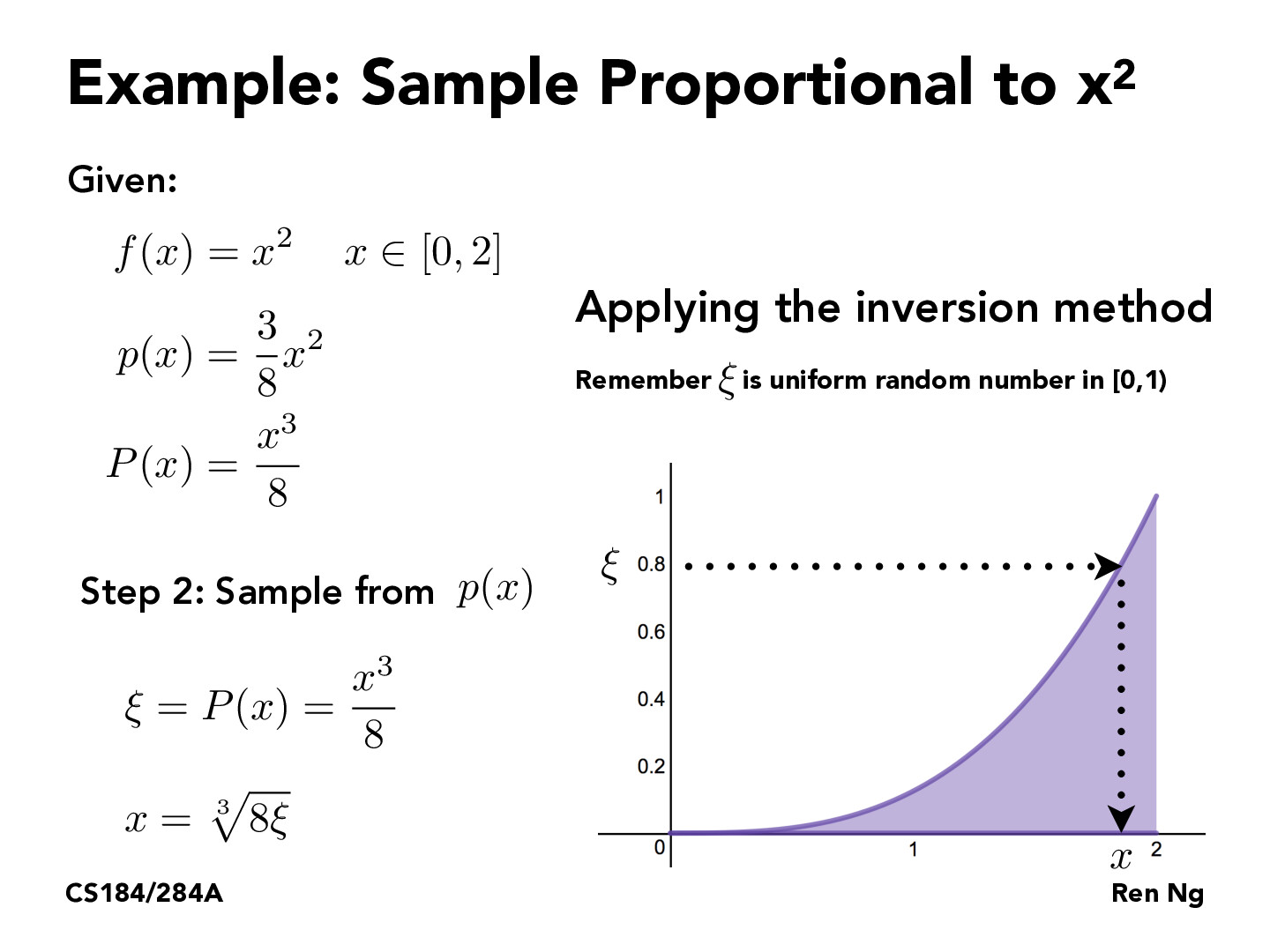
If I am understanding correctly the purpose of this method of using the inverse is basically because it allows us to generalize random sampling. In computers and applications we can randomly generate a value between 0 and 1 which our CFD will lie between and then the inverse will actually allow us to get a sample generated in the pdf that we are concerned with, allowing us to be general with any underlying distribution. While typing this I now came across another question: what if our sampling distribution did not have an inverse, are we out of options or is it not something we have to worry about because the pdfs we choose will have nice properties?