Lecture 9: Ray Tracing & Acceleration Structures (55)
randyen
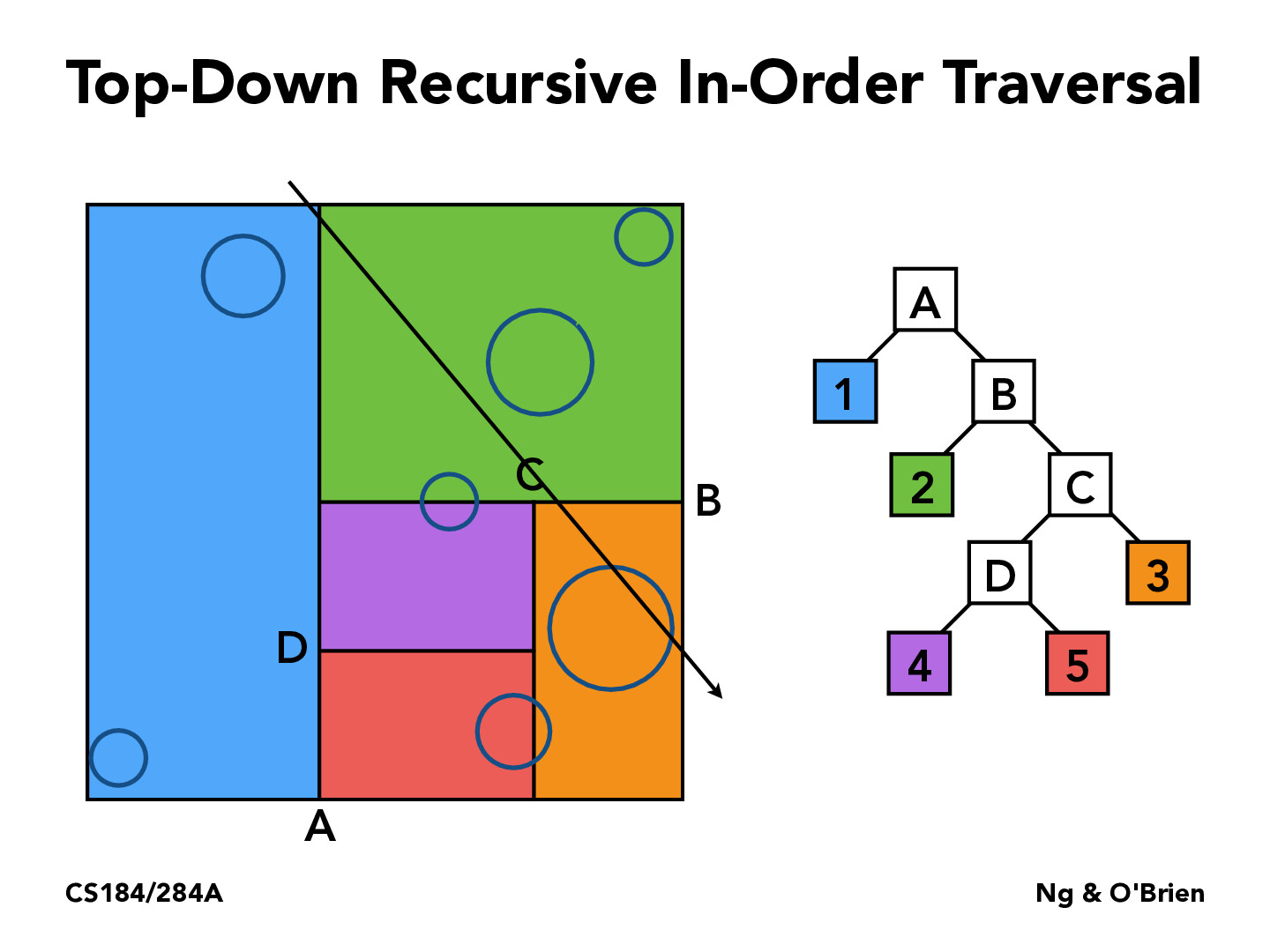
Although this algorithm states the usage of a top-down recursive in order traversal, I wonder what (if there are any) are the reasons for doing so than say, a bottom-up approach? Additionally, since this is a recursive algorithm, I wonder how computation and memory are utilized to be efficient- is there some data structure or dynamic programming aspects at play? Additionally, how does the ordering of the traversal play role (if it does)?
zeddybot
Top-down traversal makes sense to me in this case because if the ray intersects a leaf node, it must intersect the parents of the leaf node. Because of this, if we notice that the ray does not intersect a non-leaf node, we automatically know that it doesn't intersect any of the leaf nodes that are children of that non-leaf node. This means that if we are traversing top-down (i.e. checking the intersection with non-leaf nodes before checking the intersection with leaf nodes), we can potentially skip checking the intersections on some nodes, which saves us some computation time.
litony396
Are these trees stored locally or recalculated as needed? What are the reasons behind this choice?
Mehvix
@randyen What would a bottom-up approach look like?
Although this algorithm states the usage of a top-down recursive in order traversal, I wonder what (if there are any) are the reasons for doing so than say, a bottom-up approach? Additionally, since this is a recursive algorithm, I wonder how computation and memory are utilized to be efficient- is there some data structure or dynamic programming aspects at play? Additionally, how does the ordering of the traversal play role (if it does)?
Top-down traversal makes sense to me in this case because if the ray intersects a leaf node, it must intersect the parents of the leaf node. Because of this, if we notice that the ray does not intersect a non-leaf node, we automatically know that it doesn't intersect any of the leaf nodes that are children of that non-leaf node. This means that if we are traversing top-down (i.e. checking the intersection with non-leaf nodes before checking the intersection with leaf nodes), we can potentially skip checking the intersections on some nodes, which saves us some computation time.
Are these trees stored locally or recalculated as needed? What are the reasons behind this choice?
@randyen What would a bottom-up approach look like?