When we test for intersection with object inside a grid cell, we check for intersection with the whole object, not just the portion of the object that is contained in the grid cell. Here, the larger sphere is contained in the dark blue cell, so we test for intersection with our ray--which it does. However, the intersection point is not inside the dark blue grid cell, and is not the first point of intersection either (which would have been found in the next grid cell above the dark blue one). To avoid this, we check to see if the intersection point we find is within the current grid cell, but still store/cache the intersection point we found for later use so we don't have to "find" this point again
andreww334
Would an alternative solution or optimization be to only check on intersection on only the part of the object that is within the grid, performing some operation to redefine only that specific part of the surface? I'm not sure if this is even possible, but it seems like an inefficiency would exist in the case of complex objects with regions that don't end up in the grids on the path of the ray's traversal.
sayandas00
@emilyma53, I think we can still use the ray equation with the ray represented as a point (o) with a direction (d) both as Vector2Ds and then solve for intersection with the object surface (like slide 21 of Lecture 9). Its not a big deal if o lies outside the grid box, just the final intersection point (which we could check with plugging t into r(t) = o + td and checking if that lies in the grid box).
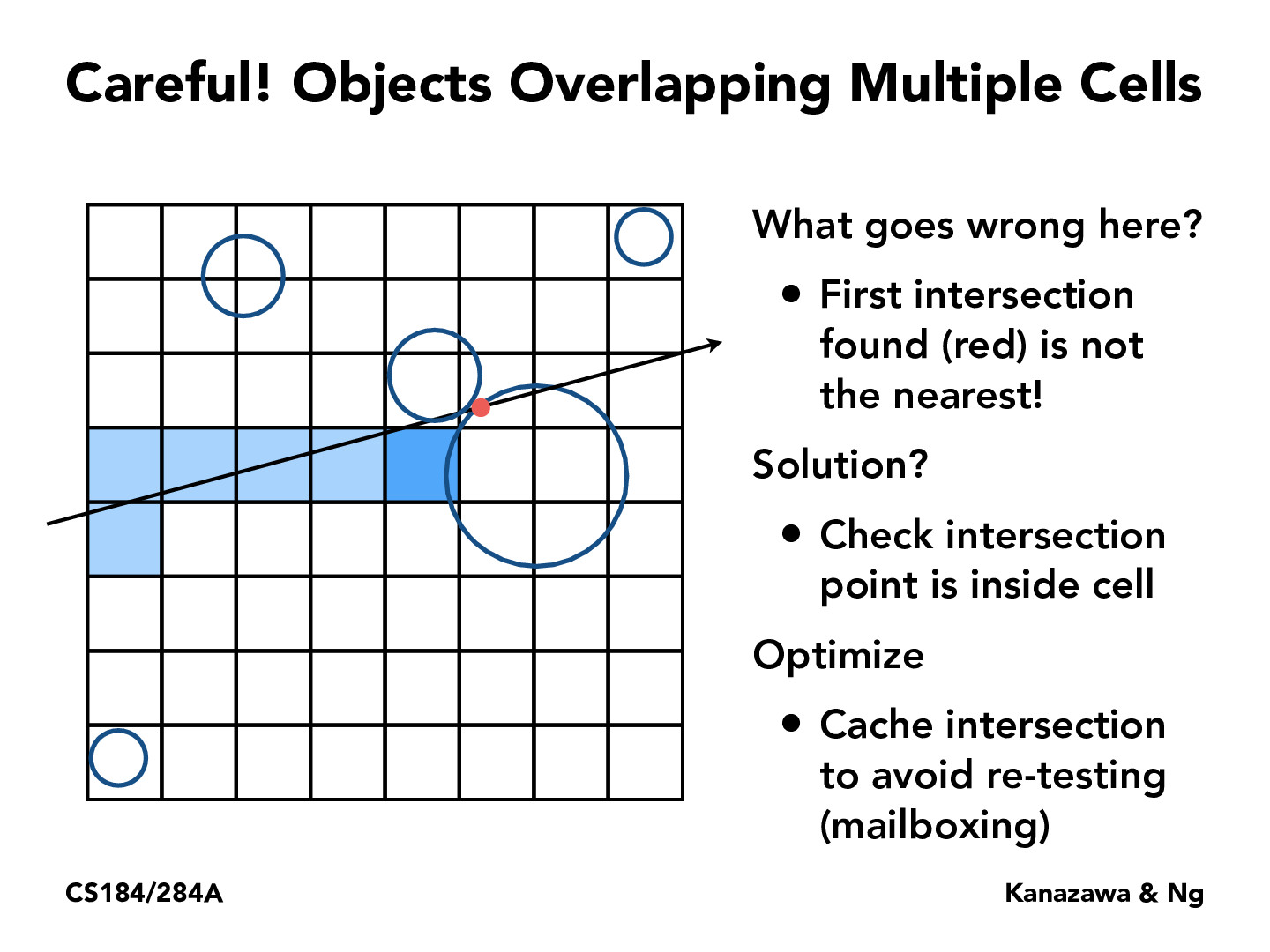
When we test for intersection with object inside a grid cell, we check for intersection with the whole object, not just the portion of the object that is contained in the grid cell. Here, the larger sphere is contained in the dark blue cell, so we test for intersection with our ray--which it does. However, the intersection point is not inside the dark blue grid cell, and is not the first point of intersection either (which would have been found in the next grid cell above the dark blue one). To avoid this, we check to see if the intersection point we find is within the current grid cell, but still store/cache the intersection point we found for later use so we don't have to "find" this point again
Would an alternative solution or optimization be to only check on intersection on only the part of the object that is within the grid, performing some operation to redefine only that specific part of the surface? I'm not sure if this is even possible, but it seems like an inefficiency would exist in the case of complex objects with regions that don't end up in the grids on the path of the ray's traversal.
@emilyma53, I think we can still use the ray equation with the ray represented as a point (o) with a direction (d) both as Vector2Ds and then solve for intersection with the object surface (like slide 21 of Lecture 9). Its not a big deal if o lies outside the grid box, just the final intersection point (which we could check with plugging t into r(t) = o + td and checking if that lies in the grid box).