How is the resolution of the bounding box for the acceleration grid decided? Is there an optimization on how many objects to store in the acceleration grid at once or does it always contain all objects in the size of the screen?
Edit: Resolution answered in following slides, a good heuristic is to use a constant x number of objects in the grid for resolution
seenumadhavan
Interesting crossover with 106A, we used an identical data structure called an "occupancy grid" when we used Lidar to map the lab room, which makes perfect sense - Lidar beams are analogous to rays of light.
seenumadhavan
Link to that lab here: https://ucb-ee106.github.io/106a-fa20site/assets/labs/106A_Lab8_Fa20_REMOTE.pdf
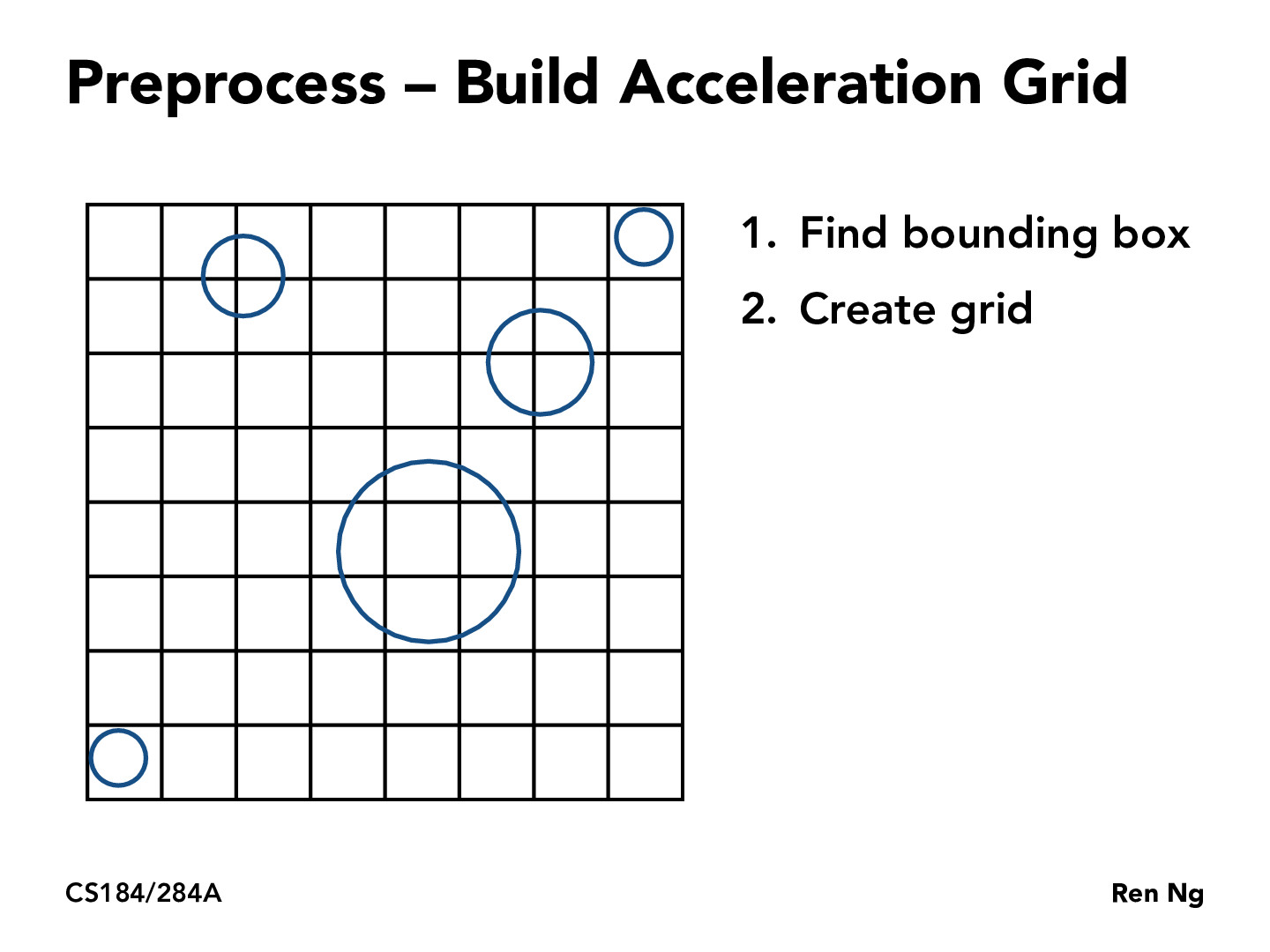
How is the resolution of the bounding box for the acceleration grid decided? Is there an optimization on how many objects to store in the acceleration grid at once or does it always contain all objects in the size of the screen?
Edit: Resolution answered in following slides, a good heuristic is to use a constant x number of objects in the grid for resolution
Interesting crossover with 106A, we used an identical data structure called an "occupancy grid" when we used Lidar to map the lab room, which makes perfect sense - Lidar beams are analogous to rays of light.
Link to that lab here: https://ucb-ee106.github.io/106a-fa20site/assets/labs/106A_Lab8_Fa20_REMOTE.pdf