f(x)/p1(x) tends to change a lot less whereas f(x)/p2(x) varies a lot more (very big for small x and very small for big x), so when doing the Monte Carlo estimate where you sum up f(Xi)/p(Xi), the variance of each individual sample will be significantly higher, so the variance of the estimator will be lower if we sample from p1 instead of p2. This seems to indicate that the "ideal" PDF would just be f(x) normalized to have unit area.
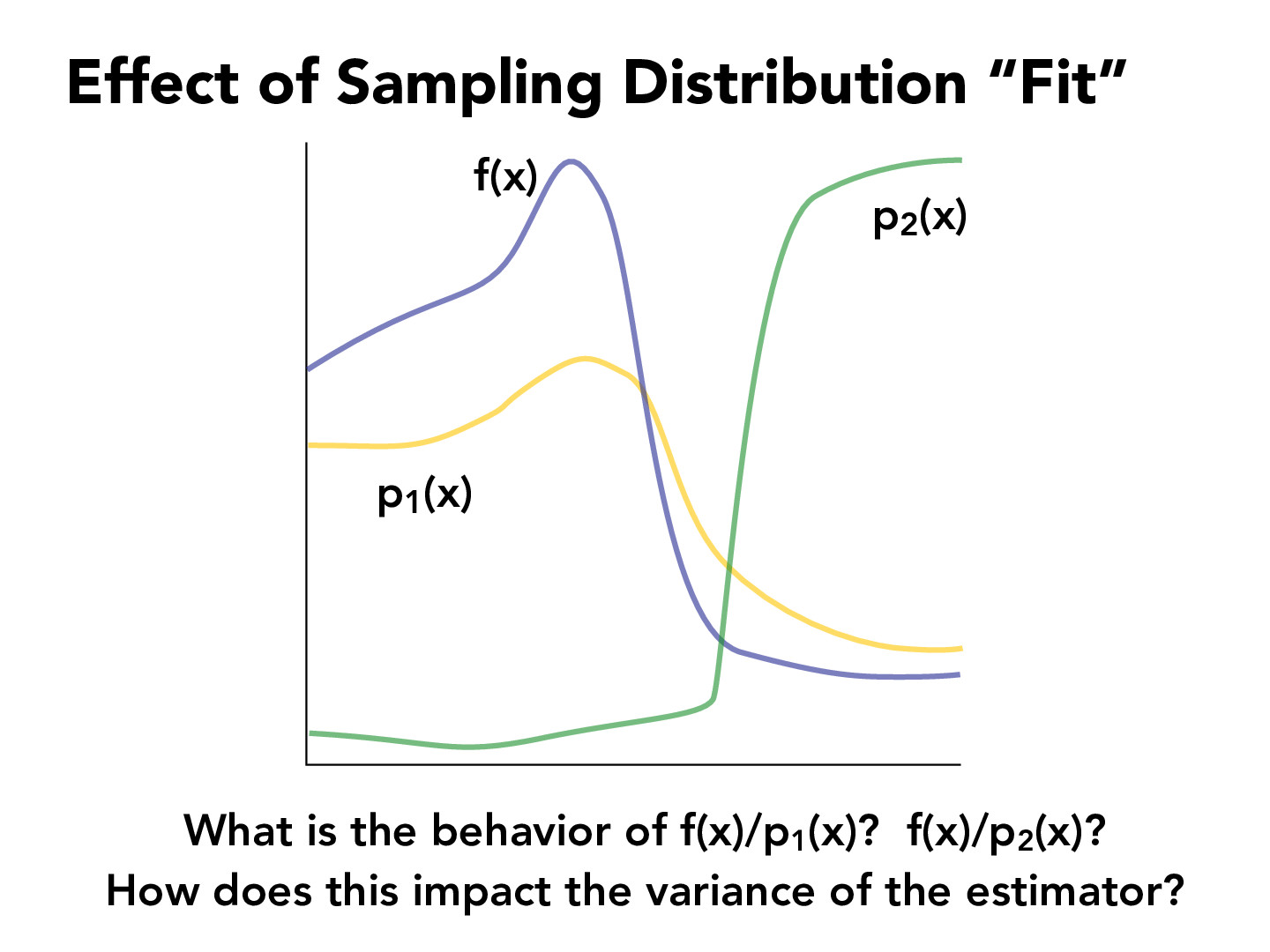
f(x)/p1(x) tends to change a lot less whereas f(x)/p2(x) varies a lot more (very big for small x and very small for big x), so when doing the Monte Carlo estimate where you sum up f(Xi)/p(Xi), the variance of each individual sample will be significantly higher, so the variance of the estimator will be lower if we sample from p1 instead of p2. This seems to indicate that the "ideal" PDF would just be f(x) normalized to have unit area.