When we design pixels, why do we only use squares, but not equiangular triangles, hexagons, or other shapes that could also be meshed tightly?
Is that because it is easier to be represented by a matrix?
sagnibak
What a "pixel" is heavily depends on context. The best way to think about what a pixel is while drawing is to think of it as a single point in space. However, there is no such thing as a point in the real world, so we must depict it using something larger than a point. One might argue that the best way to arrange these points is in a lattice with straight vertical and horizontal alignment. Then if you take these aligned points and "expand" them to be able to represent them on a screen, you end up with a rectangular grid.
Furthermore, when you want to think of capturing an image with a sensor, a single point receives zero photons exactly, so you need to count the number of photons landing in a finite area, and attribute that photon count to the single point representing your theoretical pixel which is a single point. People have actually experimented with the pixels in sensors being in hexagonal grids instead of rectangular ones, and this has some advantages, see this quora post.
In principle, it should also be possible to arrange the (point-sized) pixels in a hexagonal grid on a screen, but I couldn't find any examples with a quick google search.
The main reason most of these sensors and displays with pixels arranged in non-rectangular grids did not get popular is that it is somewhat harder to write code for them. Consider writing a rasterizer for this triangle but if the pixels are in a hexagonal grid. Instead of being able to iterate over all the rows identically, you would have to iterate in pairs of rows, and shift your sampling points back and forth horizontally/vertically, which adds a lot of complexity. While it might change (and perhaps event reduce) common aliasing artifacts, the computational tradeoff is generally not considered to be worth it.
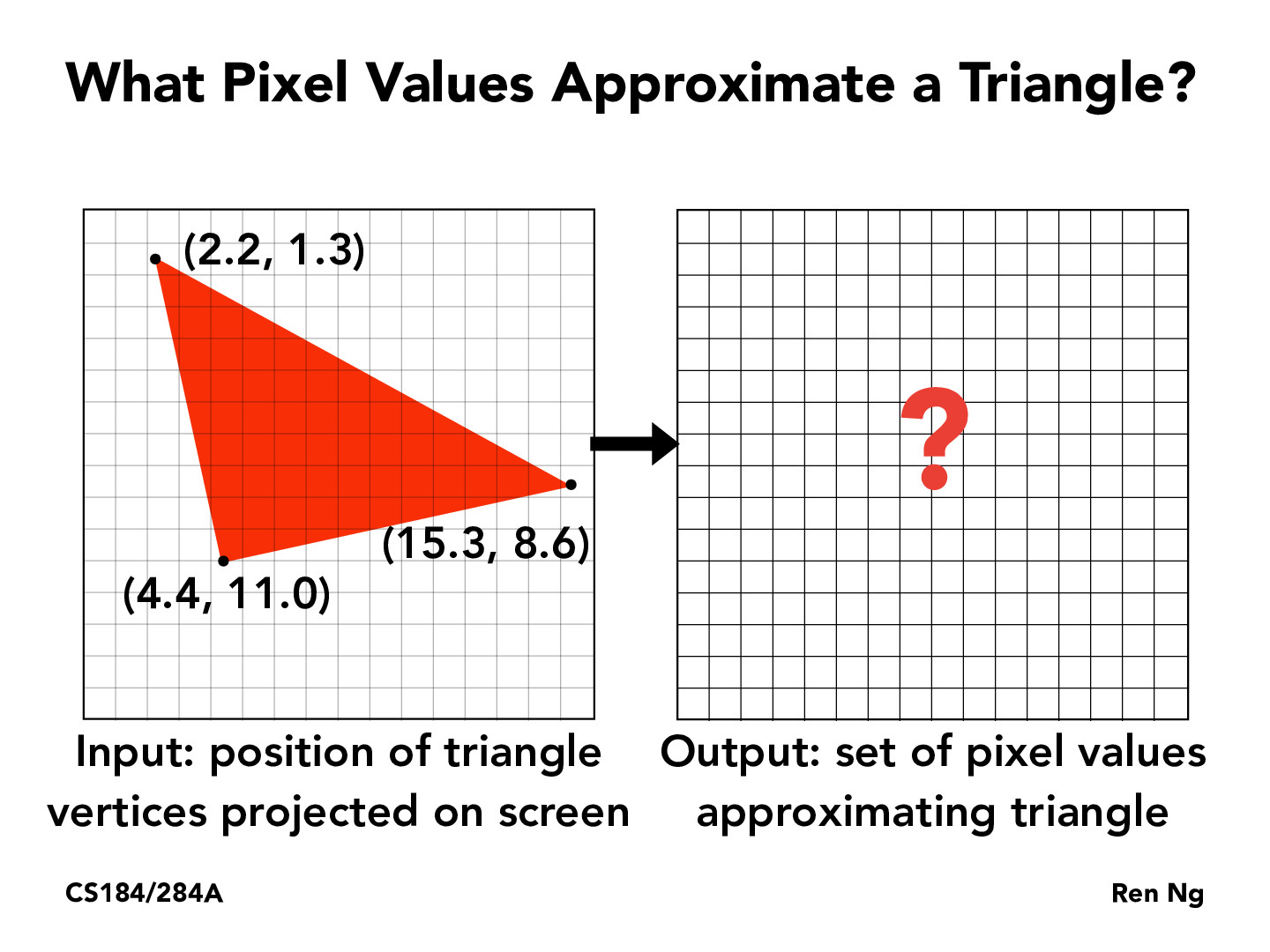
When we design pixels, why do we only use squares, but not equiangular triangles, hexagons, or other shapes that could also be meshed tightly?
Is that because it is easier to be represented by a matrix?
What a "pixel" is heavily depends on context. The best way to think about what a pixel is while drawing is to think of it as a single point in space. However, there is no such thing as a point in the real world, so we must depict it using something larger than a point. One might argue that the best way to arrange these points is in a lattice with straight vertical and horizontal alignment. Then if you take these aligned points and "expand" them to be able to represent them on a screen, you end up with a rectangular grid.
Furthermore, when you want to think of capturing an image with a sensor, a single point receives zero photons exactly, so you need to count the number of photons landing in a finite area, and attribute that photon count to the single point representing your theoretical pixel which is a single point. People have actually experimented with the pixels in sensors being in hexagonal grids instead of rectangular ones, and this has some advantages, see this quora post.
In principle, it should also be possible to arrange the (point-sized) pixels in a hexagonal grid on a screen, but I couldn't find any examples with a quick google search.
The main reason most of these sensors and displays with pixels arranged in non-rectangular grids did not get popular is that it is somewhat harder to write code for them. Consider writing a rasterizer for this triangle but if the pixels are in a hexagonal grid. Instead of being able to iterate over all the rows identically, you would have to iterate in pairs of rows, and shift your sampling points back and forth horizontally/vertically, which adds a lot of complexity. While it might change (and perhaps event reduce) common aliasing artifacts, the computational tradeoff is generally not considered to be worth it.