in this algorithm, are we comparing the neighborhood of p from the source or from what we've already synthesize?
JefferyYC
Looking at the algorithm, it might be too time costly to loop over all NxN patches of the entire image. I wonder how we could quickly locate the plausible similar regions while ignoring other patches, perhaps through some heuristics.
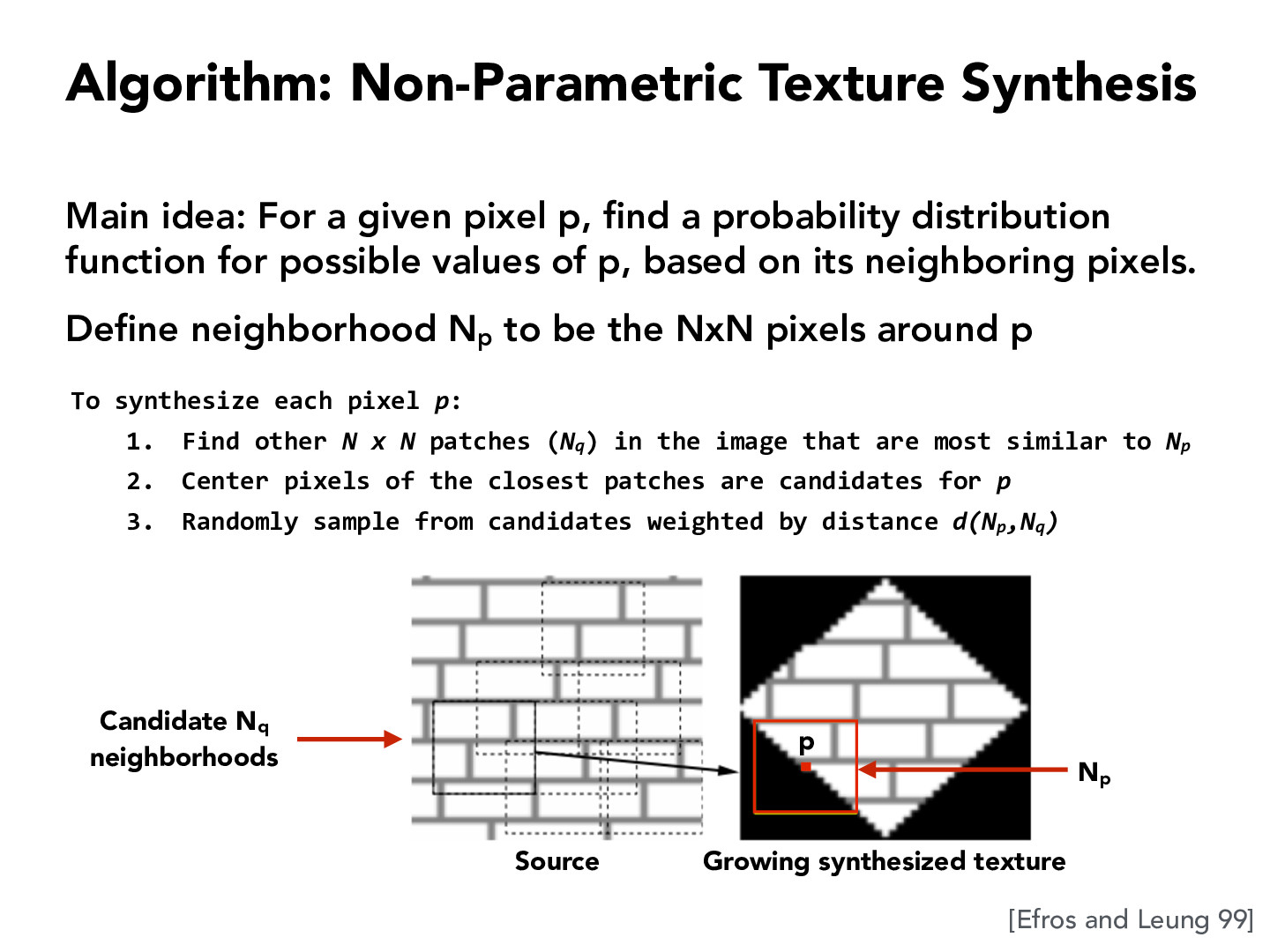
How do we choose N (the number of neighboring pixels)? Is there an empirical value that is typically used or do we choose it through trial and error?
Here is a link to their project page: https://people.eecs.berkeley.edu/~efros/research/EfrosLeung.html.
in this algorithm, are we comparing the neighborhood of p from the source or from what we've already synthesize?
Looking at the algorithm, it might be too time costly to loop over all NxN patches of the entire image. I wonder how we could quickly locate the plausible similar regions while ignoring other patches, perhaps through some heuristics.