https://medium.com/@bdhuma/6-basic-things-to-know-about-convolution-daef5e1bc411
I think this article can also help us understand convolution.
bronyayang
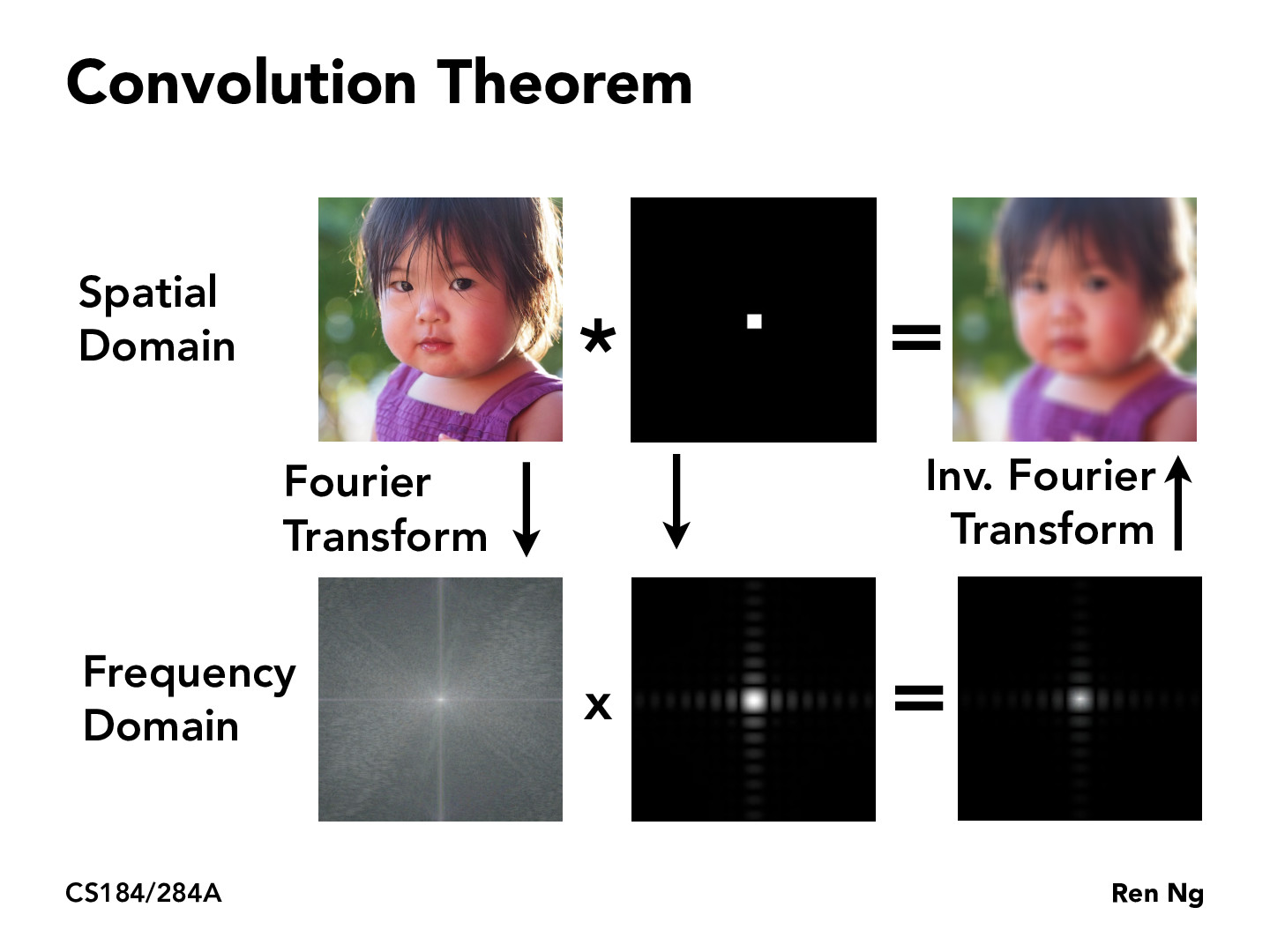
https://youtu.be/mOiY1fOROOg This video gives proof on how convolution of filter in spatial domain is the product of filter in frequency domain.
yinxudeng
In the top row (spatial domain), do we pad the box filter with 0's around it so that it has the same size as the input image? If so, wouldn't the convolution of the image and the padded box filter be a single number?
sinood
@yinxudeng I think the padded kernel (middle top) is just for the purpose of obtaining the fourier transform of the convolution filter (middle bottom). The actual convolution operation in the top row would convolve the little box filter over the large input image.
As a side note, doing convolution over the original image with a kernel bigger than 1x1 shrinks the output image (see https://www.geeksforgeeks.org/cnn-introduction-to-padding/). in CS194-26 we talked about different convolution techniques, e.g. if you have a 3x3 kernel you can pad the input image with one layer of zeros all around so that the blurred output image was the same size as the input. This however creates a darkened rim in the output, so there are other things you can do, like reusing pixels from the input image in the padding.
https://medium.com/@bdhuma/6-basic-things-to-know-about-convolution-daef5e1bc411 I think this article can also help us understand convolution.
https://youtu.be/mOiY1fOROOg This video gives proof on how convolution of filter in spatial domain is the product of filter in frequency domain.
In the top row (spatial domain), do we pad the box filter with 0's around it so that it has the same size as the input image? If so, wouldn't the convolution of the image and the padded box filter be a single number?
@yinxudeng I think the padded kernel (middle top) is just for the purpose of obtaining the fourier transform of the convolution filter (middle bottom). The actual convolution operation in the top row would convolve the little box filter over the large input image.
As a side note, doing convolution over the original image with a kernel bigger than 1x1 shrinks the output image (see https://www.geeksforgeeks.org/cnn-introduction-to-padding/). in CS194-26 we talked about different convolution techniques, e.g. if you have a 3x3 kernel you can pad the input image with one layer of zeros all around so that the blurred output image was the same size as the input. This however creates a darkened rim in the output, so there are other things you can do, like reusing pixels from the input image in the padding.