Thanks for sharing @maxqlord. I found the memory section especially relevant to the lecture material. Specifically, a GPU maintains the state of millions of triangles per scene, iterating over them in the order of 30-60 frames per second in parallel. One follow-up question I'd ask is: this diagram shows multiple independent caches in parallel (i.e., multi-core) whereas the article proposes GMEM, a global buffer unit across all processes (i.e., multi-thread-ish). Does this distinction matter for GPUs? If so, which option yields faster performance?
adityaramkumar
There's a lot of research at Berkeley and beyond on GPUs. One thing that's noteworthy is that GPUs are expensive, and while they may speedup certain workloads, they aren't necessary for all of it (some part of it may do just fine on a CPU). There are challenges around moving necessary data between CPU and GPU memory, etc. Check out KaaS and Cloudflow for systems like this being worked on at Berkeley.
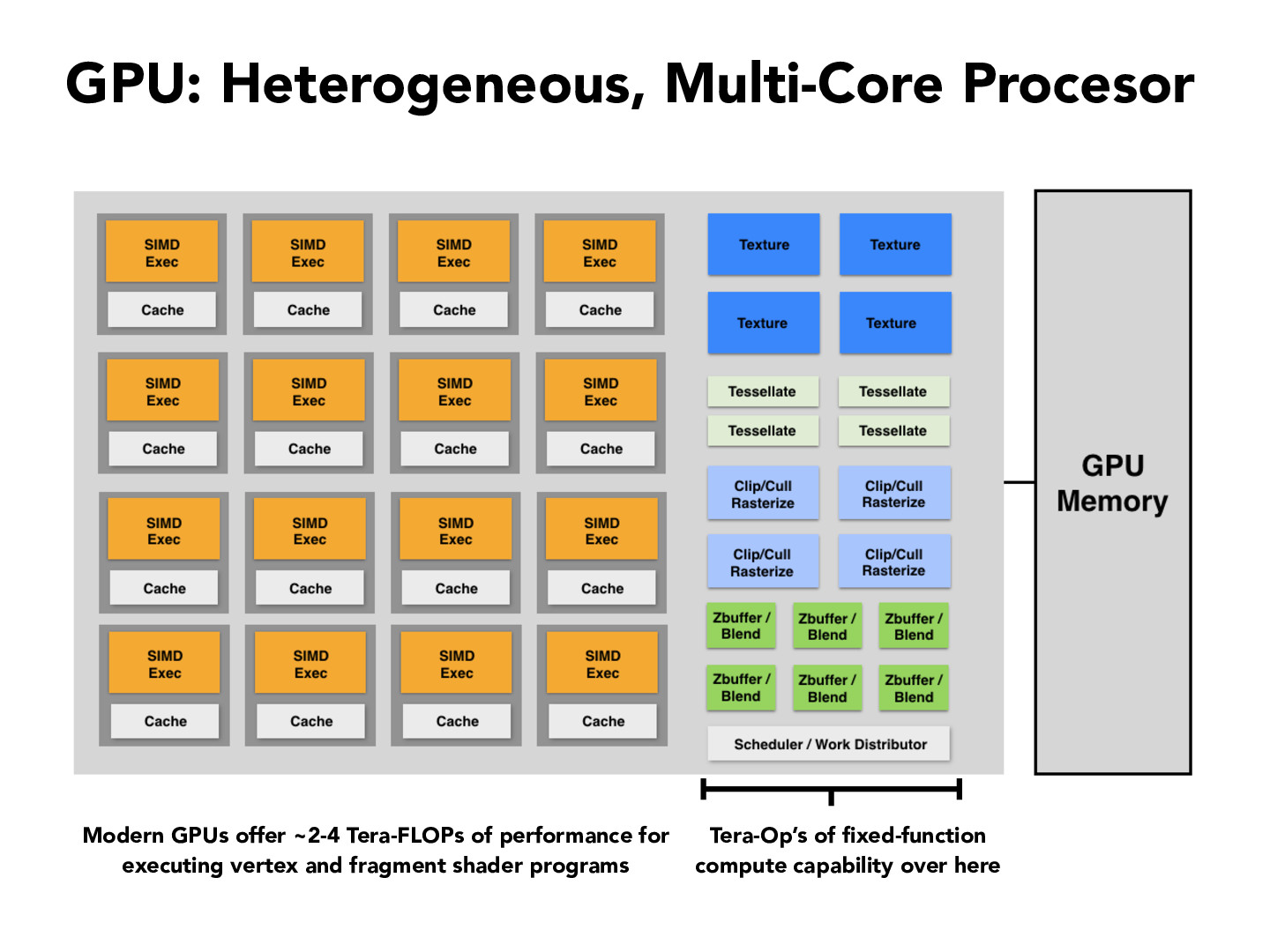
Here's a link to a more detailed technical explanation of why GPUs are better for certain workloads than CPUs: https://medium.com/codex/understanding-the-architecture-of-a-gpu-d5d2d2e8978b
Thanks for sharing @maxqlord. I found the memory section especially relevant to the lecture material. Specifically, a GPU maintains the state of millions of triangles per scene, iterating over them in the order of 30-60 frames per second in parallel. One follow-up question I'd ask is: this diagram shows multiple independent caches in parallel (i.e., multi-core) whereas the article proposes GMEM, a global buffer unit across all processes (i.e., multi-thread-ish). Does this distinction matter for GPUs? If so, which option yields faster performance?
There's a lot of research at Berkeley and beyond on GPUs. One thing that's noteworthy is that GPUs are expensive, and while they may speedup certain workloads, they aren't necessary for all of it (some part of it may do just fine on a CPU). There are challenges around moving necessary data between CPU and GPU memory, etc. Check out KaaS and Cloudflow for systems like this being worked on at Berkeley.