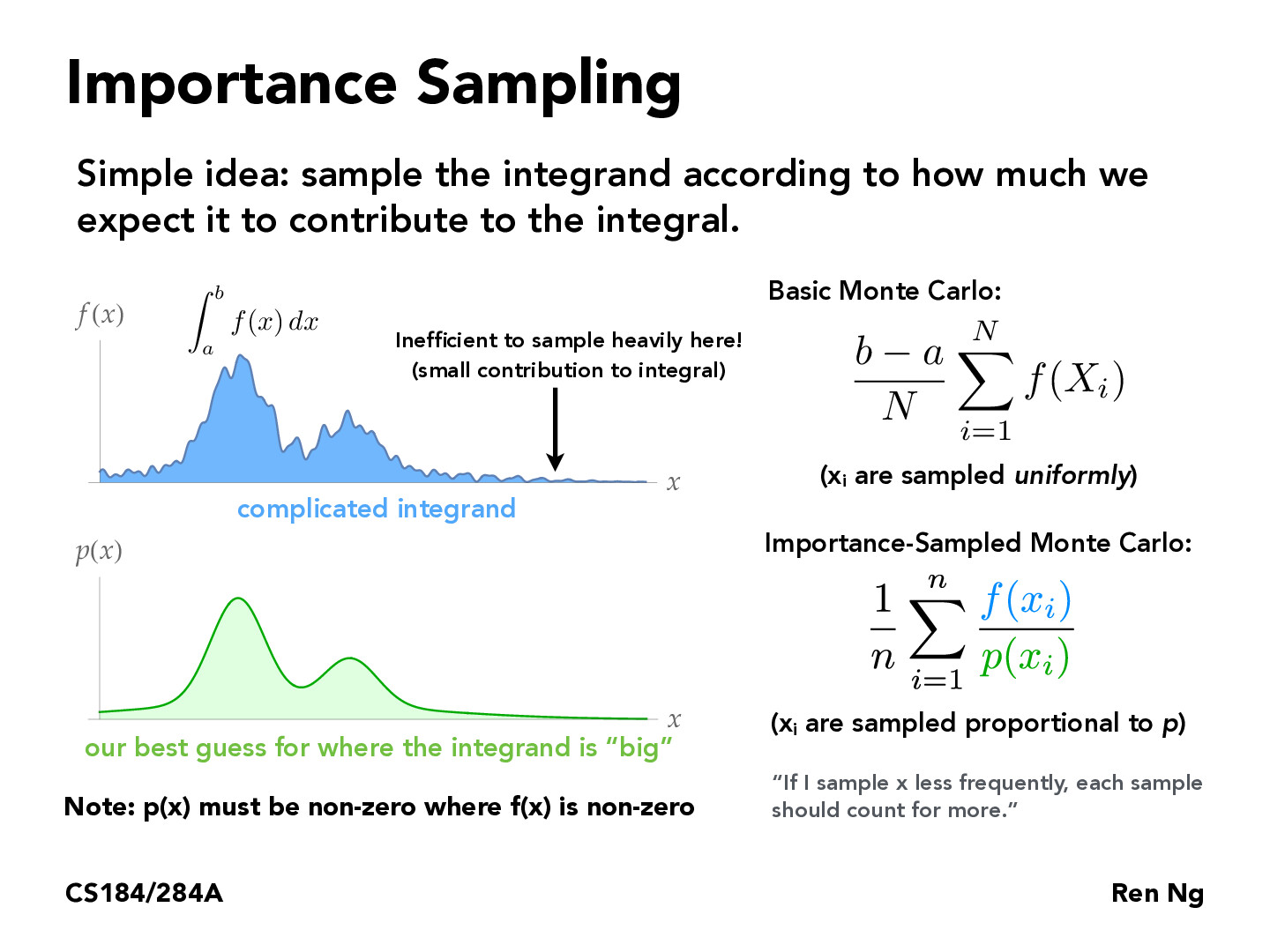
How do we find this guess p(x) in practice? Is it something that has to be precomputed before running the program, or can the code actually "learn" what a good guess for the function might be and optimize over time? I can imagine using polynomial interpolation techniques to create a better and better guess as to what the function f looks like every time you sample f (although you'd have to stop before sampling the polynomial became just as bad as sampling the function).
omijimo
how would we determine which areas are more important and sample them more without actually computing any integrals?
Edge7481
Are there scenarios where importance-sampled monte carlo produces a worse estimate than basic monte carlo?
yfyin-ian
@spegeerino There are some work in volume rendering exploiting similar ideas. One of the approaches proposed a "hierarchical" sampling method, where they first sample a "coarse" set N_c locations from [a, b] using stratified sampling. This serves as a guess of f(x) (like what p(x) does). They then sample a "fine" set of N_f locations based on the "coarse" set (which is the guess) using the inversion method discussed later in this lecture. The "fine" set will focus more on places where f(x) is larger, resulting in a more accurate color (i.e. estimate of the integral in our context). The final result uses the union of the "coarse" and "fine" set as the samples and compute the final estimate.
saif-m17
It was mentioned offhand that we need p(x) to be nonzero when f(x) is nonzero, but that this is not always easy in practice. In what scenarios does this become an issue? Do we see poor results if we assign probabilities close to zero, since the weight then becomes very large?
Zzz212zzZ
In practice, how do we get the p? In the HW3, pdf is given as an input. But how is this obtained? For one strategy I guess, the closer to the light source might have a higher probability.
grafour
@spegeerino, I think in lecture ren said that somethings it also comes with intuition of what kind of function the f(x) looks like in estimate
Rogeryu1234
The Monte Carlo Estimator is a very useful tool to generate random sampling. We can use different trial probability distributions. The one that we use in the project is just a simple uniform distribution.
brianqch
Importance sampling is pretty intuitive in the sense that we only look to sample in areas that have a greater effect on the integral. I assume then that by sampling more frequently from regions where p(x) has higher values, importance sampling can reduce the variance of the estimator. Which can mean less noise!
How do we find this guess p(x) in practice? Is it something that has to be precomputed before running the program, or can the code actually "learn" what a good guess for the function might be and optimize over time? I can imagine using polynomial interpolation techniques to create a better and better guess as to what the function f looks like every time you sample f (although you'd have to stop before sampling the polynomial became just as bad as sampling the function).
how would we determine which areas are more important and sample them more without actually computing any integrals?
Are there scenarios where importance-sampled monte carlo produces a worse estimate than basic monte carlo?
@spegeerino There are some work in volume rendering exploiting similar ideas. One of the approaches proposed a "hierarchical" sampling method, where they first sample a "coarse" set N_c locations from [a, b] using stratified sampling. This serves as a guess of f(x) (like what p(x) does). They then sample a "fine" set of N_f locations based on the "coarse" set (which is the guess) using the inversion method discussed later in this lecture. The "fine" set will focus more on places where f(x) is larger, resulting in a more accurate color (i.e. estimate of the integral in our context). The final result uses the union of the "coarse" and "fine" set as the samples and compute the final estimate.
It was mentioned offhand that we need p(x) to be nonzero when f(x) is nonzero, but that this is not always easy in practice. In what scenarios does this become an issue? Do we see poor results if we assign probabilities close to zero, since the weight then becomes very large?
In practice, how do we get the
p? In the HW3, pdf is given as an input. But how is this obtained? For one strategy I guess, the closer to the light source might have a higher probability.@spegeerino, I think in lecture ren said that somethings it also comes with intuition of what kind of function the f(x) looks like in estimate
The Monte Carlo Estimator is a very useful tool to generate random sampling. We can use different trial probability distributions. The one that we use in the project is just a simple uniform distribution.
Importance sampling is pretty intuitive in the sense that we only look to sample in areas that have a greater effect on the integral. I assume then that by sampling more frequently from regions where p(x) has higher values, importance sampling can reduce the variance of the estimator. Which can mean less noise!