In Importance Sampling, the idea is to pick samples from parts of a function that add more to the total we're trying to calculate. However, making these choices isn't always easy. If we choose a sampling method that matches the func well, we can get more accurate results with less noise. But, if our choice isn't a good match, it can make our results worse. In real-world applications, the choice of pdf not only impacts the noise level but also the computational overhead. So, an optimal strategy might be a trade-off between reducing variance and minimizing complexity. We want to get the best quality picture with the least amount of effort. Choosing where to focus can make a big difference.
kalebdawit
My initial prediction for how multiple importance sampling is implemented was that we should simply weight our integrand samples by a randomly chosen probability distribution (in this slide's example, randomly choose between p1(x) and p2(x)). But this would lead to variance as there might be a mismatch between the f(x) sample value and the chosen probability distribution value. For instance, what if our f(x) sample is at the top of the first peak and we randomly choose to weight it by the corresponding p2(x) value. This strategy would erroneously result in us blowing up that sample value. The Multiple Importance Sampling section here (https://www.pbr-book.org/3ed-2018/Monte_Carlo_Integration/Importance_Sampling) provides more advanced solutions.
grafour
I really think that this method is such a smart idea as using a smoother p(x) can save a lot of time in computing the range of the function.
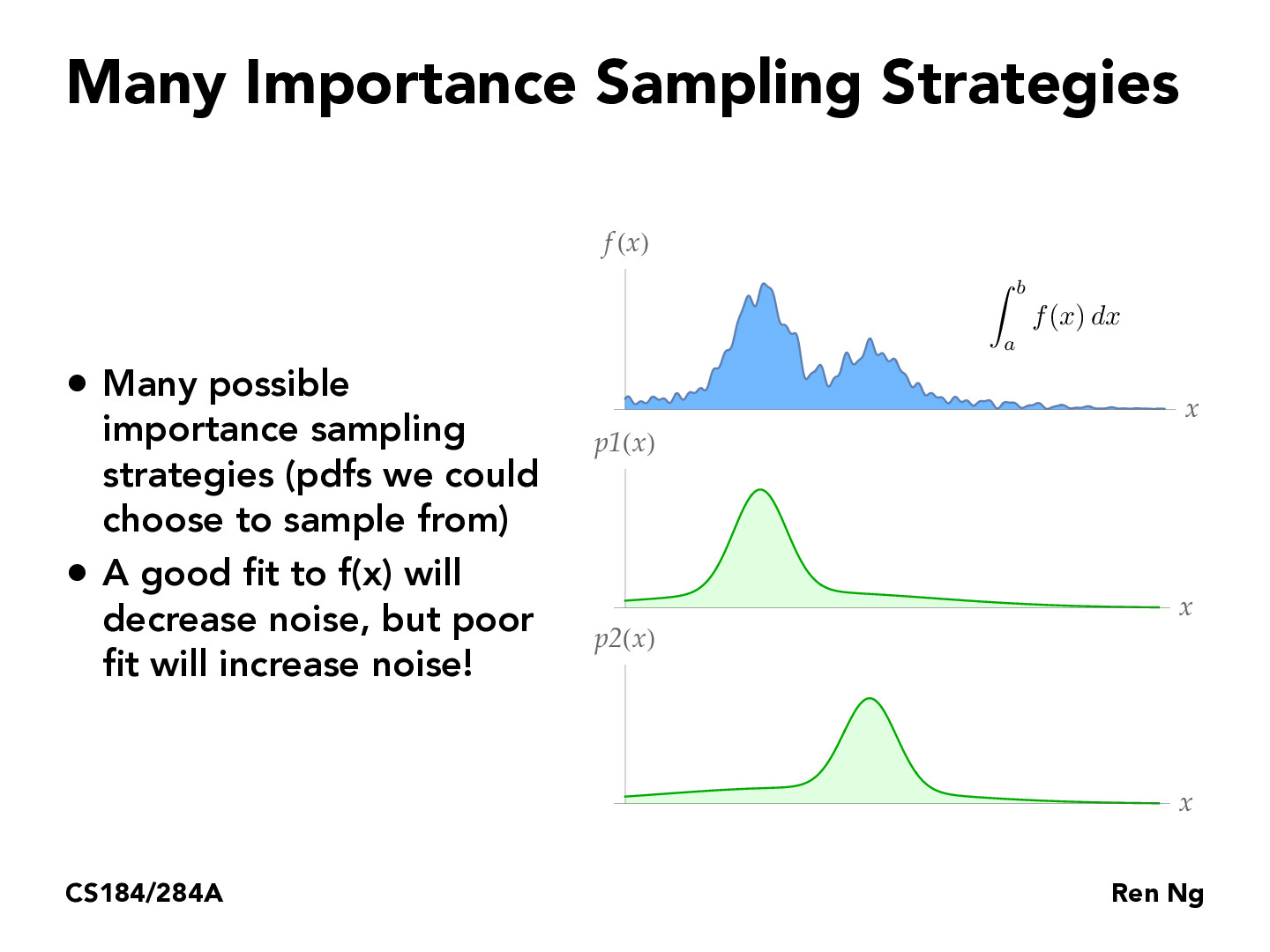
In Importance Sampling, the idea is to pick samples from parts of a function that add more to the total we're trying to calculate. However, making these choices isn't always easy. If we choose a sampling method that matches the func well, we can get more accurate results with less noise. But, if our choice isn't a good match, it can make our results worse. In real-world applications, the choice of pdf not only impacts the noise level but also the computational overhead. So, an optimal strategy might be a trade-off between reducing variance and minimizing complexity. We want to get the best quality picture with the least amount of effort. Choosing where to focus can make a big difference.
My initial prediction for how multiple importance sampling is implemented was that we should simply weight our integrand samples by a randomly chosen probability distribution (in this slide's example, randomly choose between p1(x) and p2(x)). But this would lead to variance as there might be a mismatch between the f(x) sample value and the chosen probability distribution value. For instance, what if our f(x) sample is at the top of the first peak and we randomly choose to weight it by the corresponding p2(x) value. This strategy would erroneously result in us blowing up that sample value. The Multiple Importance Sampling section here (https://www.pbr-book.org/3ed-2018/Monte_Carlo_Integration/Importance_Sampling) provides more advanced solutions.
I really think that this method is such a smart idea as using a smoother p(x) can save a lot of time in computing the range of the function.