How would reordering algorithms work? My guess would be to reorder data to have larger groups of consistent data to be able to compress that information. So for example, instead of storing the data for 10 identical green pixels, you store 10 * green, for 10% of the space. Firstly, are these reordering pixels standard or produced based on the image? If they are produced image to image, how is the reconstruction data created and stored, and how long does it take to find a meaningful reorder?
buggy213
this is just a canonical way to reorder the DCT coefficients, i don't think it varies based on the image. the idea is that since you quantized the high frequency components more aggressively, the bottom right side of the DCT matrix is extremely sparse, so you can compress it very easily with run-length encoding
TiaJain
Given that Huffman coding depends on the frequency of symbol occurrences, how does the nature of the image content affect the efficiency of the JPEG compression? For instance, would an image with large areas of uniform color compress more effectively than one with varied details?
ShonenMind
@TiaJain That's a really interesting question! In terms of Huffman coding, we can see that probably images with a very DIVERSE set of pixels will work much worse with huffman encoding (because we have a larger "alphabet", so to speak), whereas very dark images with mostly black pixels will do pretty well, as most of the pixels will fall onto that category of black pixels.
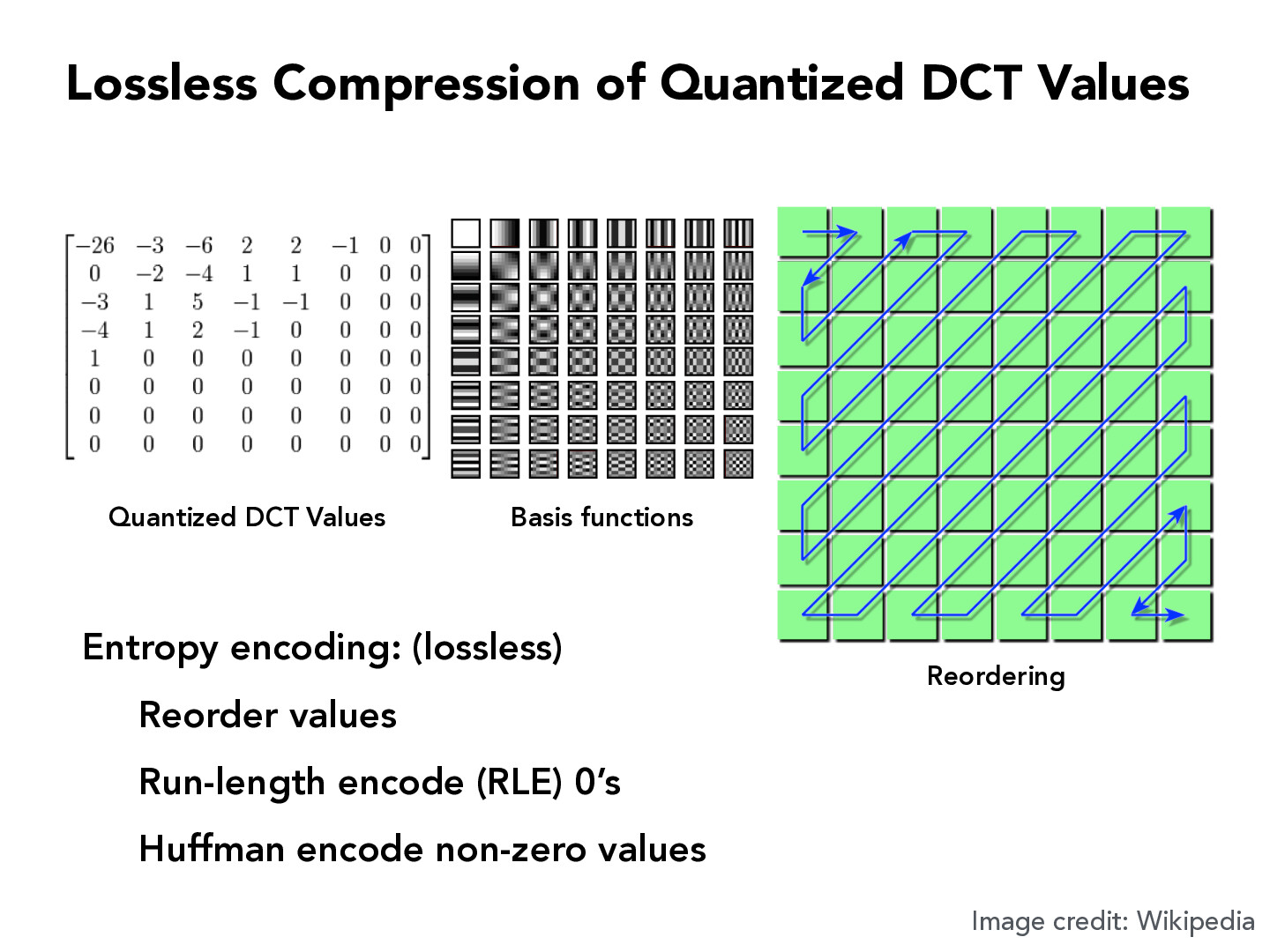
How would reordering algorithms work? My guess would be to reorder data to have larger groups of consistent data to be able to compress that information. So for example, instead of storing the data for 10 identical green pixels, you store 10 * green, for 10% of the space. Firstly, are these reordering pixels standard or produced based on the image? If they are produced image to image, how is the reconstruction data created and stored, and how long does it take to find a meaningful reorder?
this is just a canonical way to reorder the DCT coefficients, i don't think it varies based on the image. the idea is that since you quantized the high frequency components more aggressively, the bottom right side of the DCT matrix is extremely sparse, so you can compress it very easily with run-length encoding
Given that Huffman coding depends on the frequency of symbol occurrences, how does the nature of the image content affect the efficiency of the JPEG compression? For instance, would an image with large areas of uniform color compress more effectively than one with varied details?
@TiaJain That's a really interesting question! In terms of Huffman coding, we can see that probably images with a very DIVERSE set of pixels will work much worse with huffman encoding (because we have a larger "alphabet", so to speak), whereas very dark images with mostly black pixels will do pretty well, as most of the pixels will fall onto that category of black pixels.