Why are we computing the CDF?
If we are sampling r.v. X, and if U is uniform [0,1] then inverse_CDF(U) = X
This is because inverse_CDF(x) = P(U < F(x)) = P(inverse_CDF(U) < x) since inverse_CDF(U) has inverse_CDF as its CDF, it is the random variable X.
Also the reason why F(x) = P(U < F(x)) is that the probability of a uniform [0,1] being less than a value u in [0,1] is just u.
Proof is from here:
https://en.wikipedia.org/wiki/Inverse_transform_sampling#Proof_of_correctness
Here's a very good video explaining how too calculate a CDF from a continuous PDF: https://www.youtube.com/watch?v=WDGyFeuk9oI&t=325s
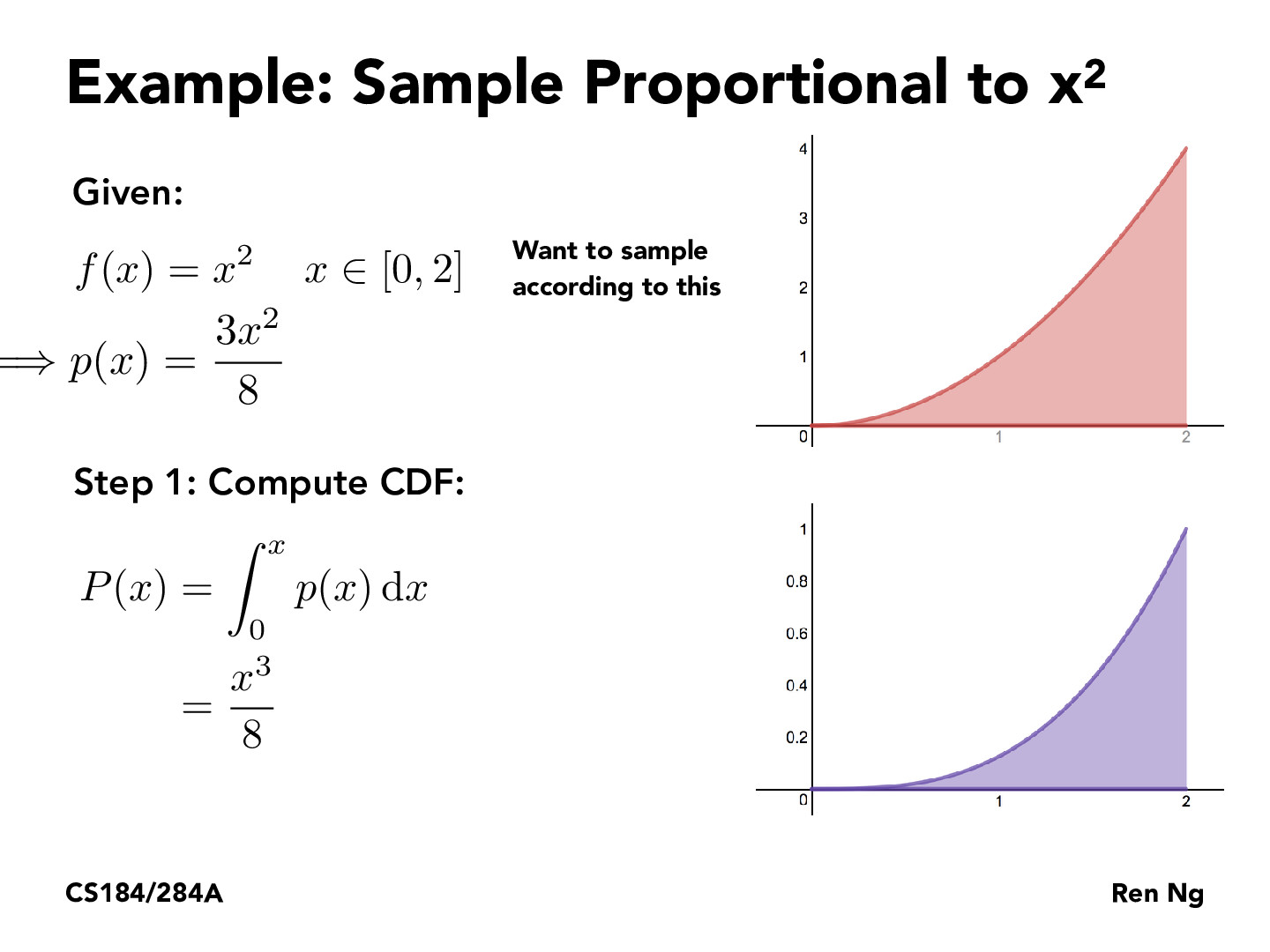
Why are we computing the CDF?
If we are sampling r.v. X, and if U is uniform [0,1] then inverse_CDF(U) = X
This is because inverse_CDF(x) = P(U < F(x)) = P(inverse_CDF(U) < x) since inverse_CDF(U) has inverse_CDF as its CDF, it is the random variable X.
Also the reason why F(x) = P(U < F(x)) is that the probability of a uniform [0,1] being less than a value u in [0,1] is just u.
Proof is from here:
https://en.wikipedia.org/wiki/Inverse_transform_sampling#Proof_of_correctness
Here's a very good video explaining how too calculate a CDF from a continuous PDF: https://www.youtube.com/watch?v=WDGyFeuk9oI&t=325s