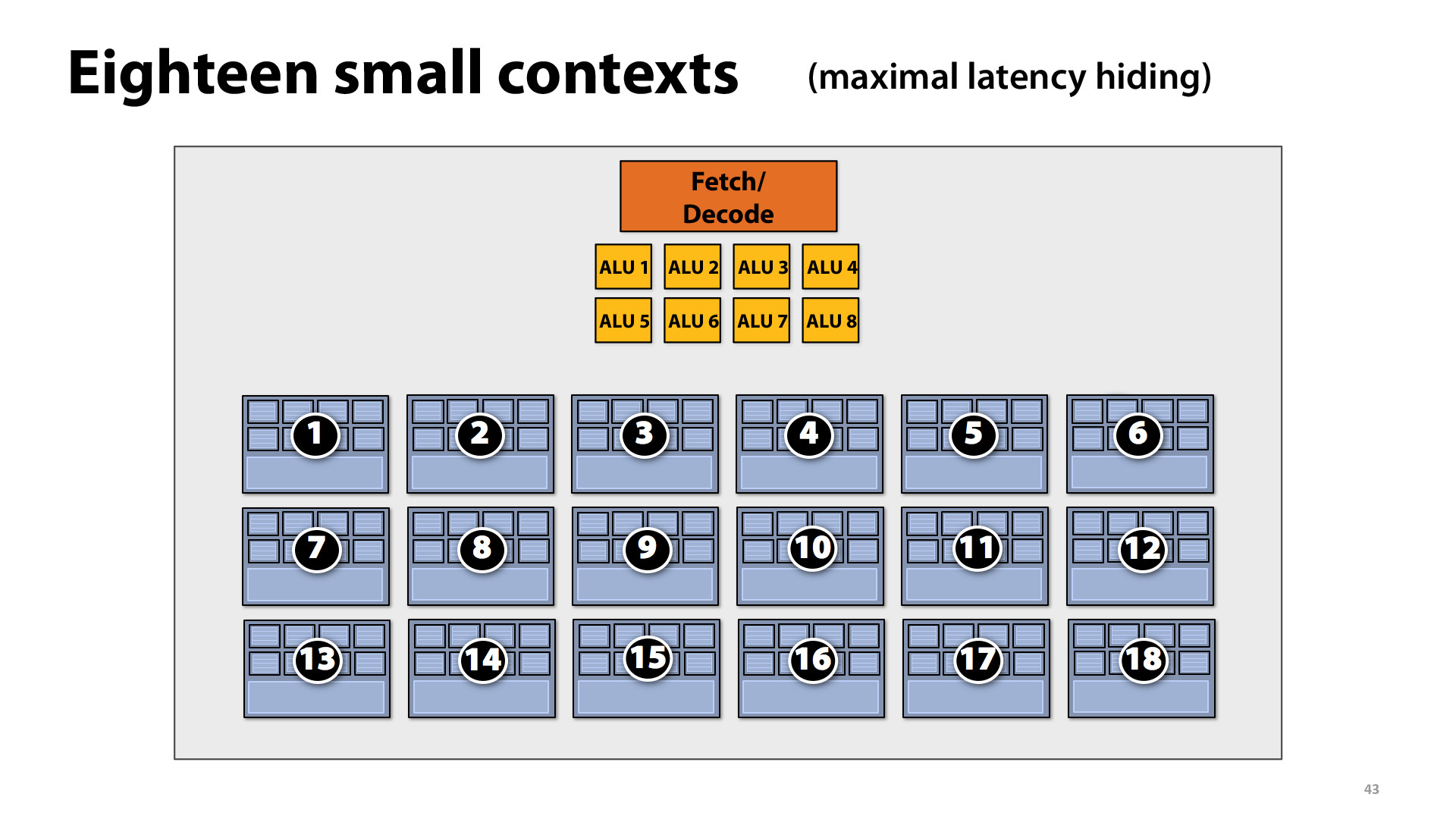
Is this saying that the less state we need to store for each pixel (smaller storage contexts), the lower the latency because we need to communicate with/write to memory less and our machine has more time to compute?
EmmmaTao
I think it means that storing more smaller contexts can enable better latency hiding because the GPU can switch to process other contexts when one context is at a stall. However, I am not sure how the contexts are sectioned differently based on their storage demands.
tigreezy
It just means that when there are smaller contexts, we can be executing more instruction streams "simultaneously" because there are more contexts to switch to when others are stalled. Since the contexts are smaller, we can store more in the predefined space. When the contexts are larger, then we have less space, so less contexts can be running at the same time.
Is this saying that the less state we need to store for each pixel (smaller storage contexts), the lower the latency because we need to communicate with/write to memory less and our machine has more time to compute?
I think it means that storing more smaller contexts can enable better latency hiding because the GPU can switch to process other contexts when one context is at a stall. However, I am not sure how the contexts are sectioned differently based on their storage demands.
It just means that when there are smaller contexts, we can be executing more instruction streams "simultaneously" because there are more contexts to switch to when others are stalled. Since the contexts are smaller, we can store more in the predefined space. When the contexts are larger, then we have less space, so less contexts can be running at the same time.