So for a better chip we can just double the amount of cores to double the performance? Are there bottlenecks when we collect all the output?
tristanburke
^ On a similar vein, I've heard of certain PC builds where users have included dual GPUs. Does this experience bottleneck, if not, is there a point of diminishing returns however?
henryzxu
For Nvidia's dual GPU solution, SLI/NVLink, the first bottleneck would be developer support, as drivers need to be updated with SLI profiles. Beyond that, benchmarks indicate not quite a simple double the GPU double the performance--it really depends on the workload (I'm a little fuzzy on specifics, however). Additionally, with SLI, you could only use the VRAM of one GPU, but NVLink (Nvidia's newest iteration of multiple GPU support) allows for the summing of VRAM from all GPUs.
zehric
I think the intuition behind this appears at all levels of any kind of parallelization; since not every part of all computations are parallelizable the serial part will always prevent 2x the number of computing units to actually provide 2x the performance in the real world.
nebster100
Another interesting thing to consider is the limits on how fast a single chip can get. The current max on an overclocked chip is ~8GHz
dtseng
Is this the main way that GPUs get faster? There's quite a lot of variance between the GPUs I've used. For example, the Amazon AWS p2x.large's Nvidia K80 is up to 3-5x slower than the V100 when I'm training neural networks.
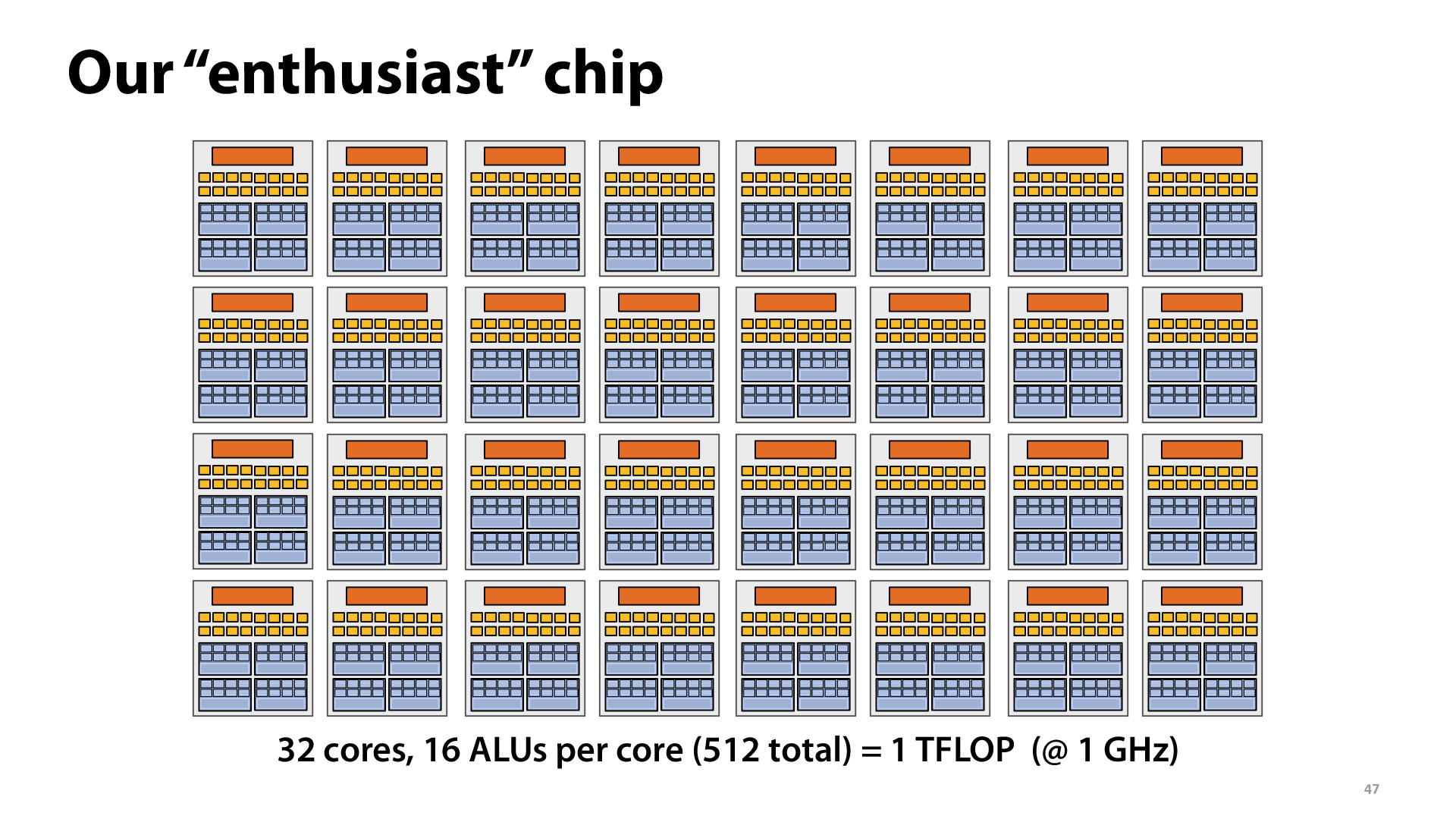
So for a better chip we can just double the amount of cores to double the performance? Are there bottlenecks when we collect all the output?
^ On a similar vein, I've heard of certain PC builds where users have included dual GPUs. Does this experience bottleneck, if not, is there a point of diminishing returns however?
For Nvidia's dual GPU solution, SLI/NVLink, the first bottleneck would be developer support, as drivers need to be updated with SLI profiles. Beyond that, benchmarks indicate not quite a simple double the GPU double the performance--it really depends on the workload (I'm a little fuzzy on specifics, however). Additionally, with SLI, you could only use the VRAM of one GPU, but NVLink (Nvidia's newest iteration of multiple GPU support) allows for the summing of VRAM from all GPUs.
I think the intuition behind this appears at all levels of any kind of parallelization; since not every part of all computations are parallelizable the serial part will always prevent 2x the number of computing units to actually provide 2x the performance in the real world.
Another interesting thing to consider is the limits on how fast a single chip can get. The current max on an overclocked chip is ~8GHz
Is this the main way that GPUs get faster? There's quite a lot of variance between the GPUs I've used. For example, the Amazon AWS p2x.large's Nvidia K80 is up to 3-5x slower than the V100 when I'm training neural networks.