Here’s an interesting article that takes advantage of the fact that the image is going to be rendered to a relatively coarse-grain grid in order to reduce the number of bits used to represent colors, positions, etc. earlier on in the pipeline. It makes sense when you consider that there is so much precise detail in the world coordinates that doesn’t really make it into the output. https://www.cs.umd.edu/gvil/papers/hao_av_i3d01.pdf
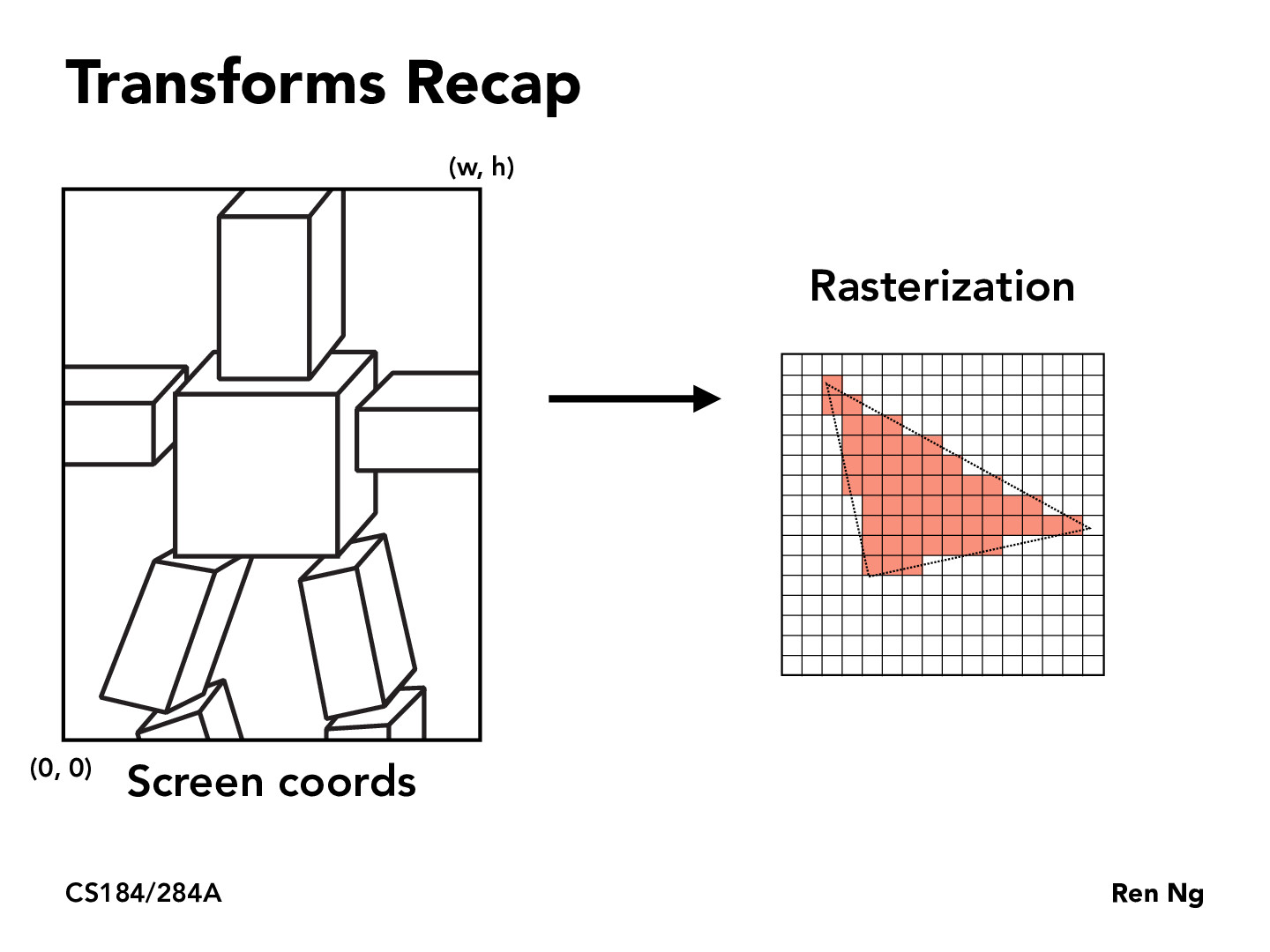
Here’s an interesting article that takes advantage of the fact that the image is going to be rendered to a relatively coarse-grain grid in order to reduce the number of bits used to represent colors, positions, etc. earlier on in the pipeline. It makes sense when you consider that there is so much precise detail in the world coordinates that doesn’t really make it into the output. https://www.cs.umd.edu/gvil/papers/hao_av_i3d01.pdf