Is there any scenario where we would prefer this over the previous equation for calculating the coefficients? I'd imagine that finding the areas would be computationally more difficult than calculating line equations.
nipunramk
Going off the previous comment, how do we calculate the areas in the most efficient manner? Do we find perpendicular bisectors for each triangle, find the height of those bisectors and then calculate the area, or do we calculate the area through other means (e.g Heron's formula https://en.wikipedia.org/wiki/Heron%27s_formula)
sphindle1
Answering the first question, I suppose in the case of a right triangle, it would be much easier to use these equations instead since the areas are easy to calculate. But in most cases, it would seem like the previous equations would be a better option.
yzyz
Calculating triangle areas can actually be done very easily using cross products. Recall that |u x v| = |u||v|sin(theta), which is equal to the area of the parallelogram formed by u and v. Half of this value gives the area of the triangle formed by u and v. So the area of ABC, for example, is |AB x AC| / 2. This division by 2 cancels out when computing barycentric coordinates, since they are a ratio of areas. Furthermore, cross products are very easy to compute in 2D, since if u and v lie in the xy-plane, u x v lies along the z-axis, so we only need to compute the z-component. Also, if we explicitly write out the formula for cross products, we get the exact same equations on the previous slide. So these two methods are equivalent.
killawhale2
The equivalency of the two methods is the not real point here. The two methods are of course equivalent otherwise they would yield different barycentric coordinates for the same point P. What's actually of interest is the computational cost difference between the two methods when implemented into actual hardware. I would imagine that this method would be more efficient to do in some cases where the shape of the triangle is known, but otherwise, I don't see how this could be computationally cheaper to the method before.
yzyz
The two methods are equivalent because they yield exactly the same equations. Once you have the equation, it doesn't really matter which method was used to derive it, since the computer is still doing the exact same calculations, and so I wouldn't consider any method computationally cheaper than the other. I would imagine that any special case optimizations you could apply to one method has an equivalent interpretation in the other method, since the underlying equations are the same.
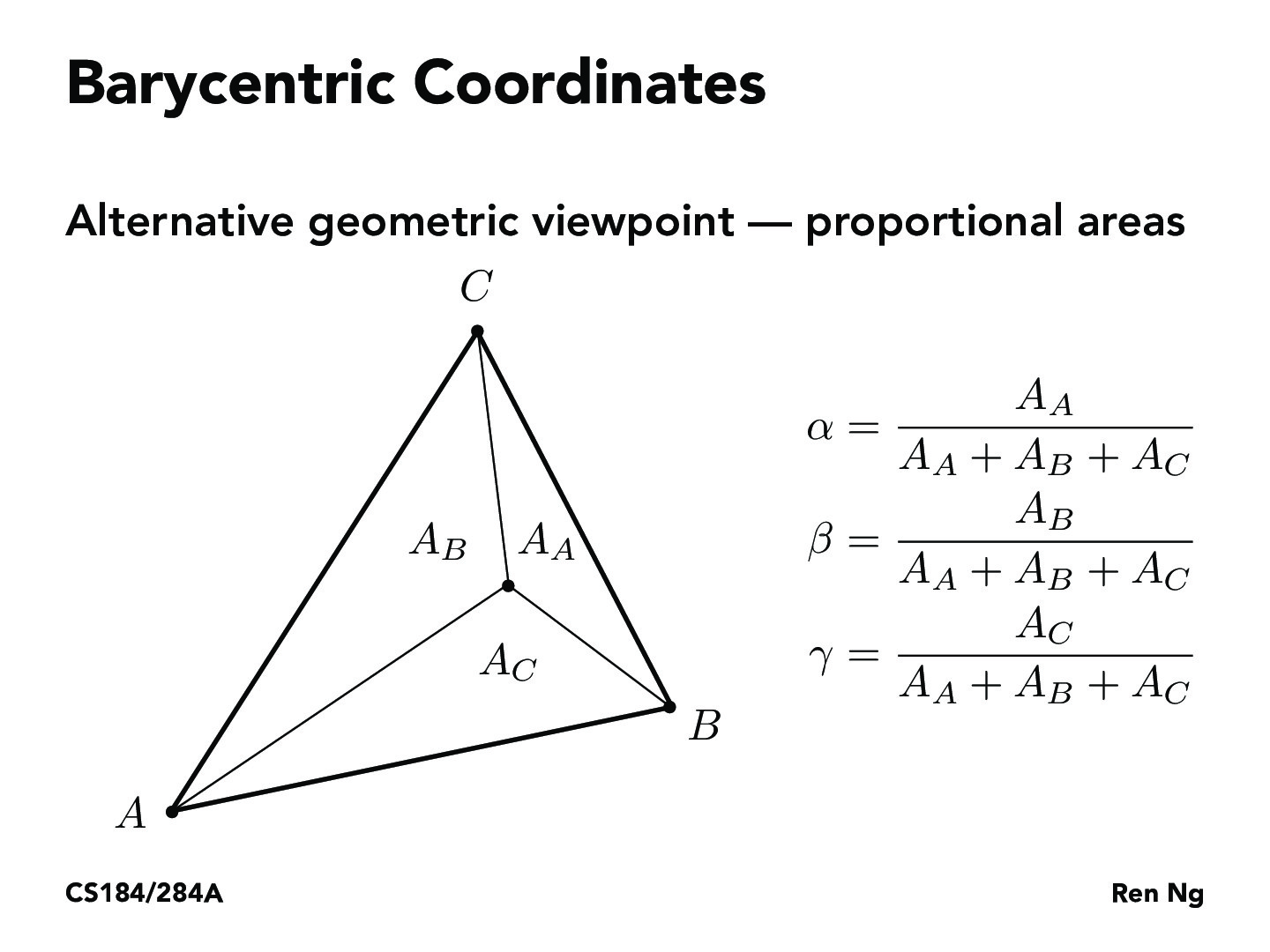
Is there any scenario where we would prefer this over the previous equation for calculating the coefficients? I'd imagine that finding the areas would be computationally more difficult than calculating line equations.
Going off the previous comment, how do we calculate the areas in the most efficient manner? Do we find perpendicular bisectors for each triangle, find the height of those bisectors and then calculate the area, or do we calculate the area through other means (e.g Heron's formula https://en.wikipedia.org/wiki/Heron%27s_formula)
Answering the first question, I suppose in the case of a right triangle, it would be much easier to use these equations instead since the areas are easy to calculate. But in most cases, it would seem like the previous equations would be a better option.
Calculating triangle areas can actually be done very easily using cross products. Recall that |u x v| = |u||v|sin(theta), which is equal to the area of the parallelogram formed by u and v. Half of this value gives the area of the triangle formed by u and v. So the area of ABC, for example, is |AB x AC| / 2. This division by 2 cancels out when computing barycentric coordinates, since they are a ratio of areas. Furthermore, cross products are very easy to compute in 2D, since if u and v lie in the xy-plane, u x v lies along the z-axis, so we only need to compute the z-component. Also, if we explicitly write out the formula for cross products, we get the exact same equations on the previous slide. So these two methods are equivalent.
The equivalency of the two methods is the not real point here. The two methods are of course equivalent otherwise they would yield different barycentric coordinates for the same point P. What's actually of interest is the computational cost difference between the two methods when implemented into actual hardware. I would imagine that this method would be more efficient to do in some cases where the shape of the triangle is known, but otherwise, I don't see how this could be computationally cheaper to the method before.
The two methods are equivalent because they yield exactly the same equations. Once you have the equation, it doesn't really matter which method was used to derive it, since the computer is still doing the exact same calculations, and so I wouldn't consider any method computationally cheaper than the other. I would imagine that any special case optimizations you could apply to one method has an equivalent interpretation in the other method, since the underlying equations are the same.