Is there any benefit for using one over the other? Is there a particular algorithm that is used in practice more often than the other?
fywu85
For partitions, is there any existing methods that use clustering techniques, such as k-means clustering or DBSCAN? If so, what is the pros and cons of clustering-based partitions as compared to say spatial or object partitions?
sunsarah
In the example given, what happens when one of the triangles (e.g. the big blue one in the left bounding box) is technically contained in the two object partitions? I assume that it will only be counted for once in the box that fully contains it, and ignored in the other, but does the second bounding box test to tell if it contains the object fully when deciding if it stores it? Or is the bounding box created after you decide which triangles belong in which bounding box?
jenzou
To sunsarah: I think that if one of the triangles is "contained" in two object partitions, then it's only counted in the one that fully contains it. The first bullet point under "Object partition" says that the set of objects are "disjoint subsets" so each object would only belong to one partition.
jenzou
Also to sunsarah: I think that the bounding box is created after deciding which triangles belong in which bounding box, based on slides 71 https://cs184.eecs.berkeley.edu/sp19/lecture/9-71/raytracing and 72 https://cs184.eecs.berkeley.edu/sp19/lecture/9-72/raytracing. In preprocessing we define the bounding boxes, recursively split into two subsets, and continue until the termination criteria. Also I think the bounding box is just an identification variable under each node (slide 71). The bounding box wouldn't track objects that are not fully contained within it, especially because the sets are disjoint, so all objects "inside" a bounding box are considered to be fully inside of it, and partially contained objects are disregarded. (I hope this is correct)
muminovic
This paper goes into a technical analysis and comparison of various ways to apply spatial partitioning in large-scale, real-time crowd simulations if anyone is interested in a real-world application and a more detailed look into tradeoffs of different data structures: https://dspace5.zcu.cz/bitstream/11025/10652/1/Li.pdf
(Page 4 has some cool visualizations of how it actually works on different sized data sets)
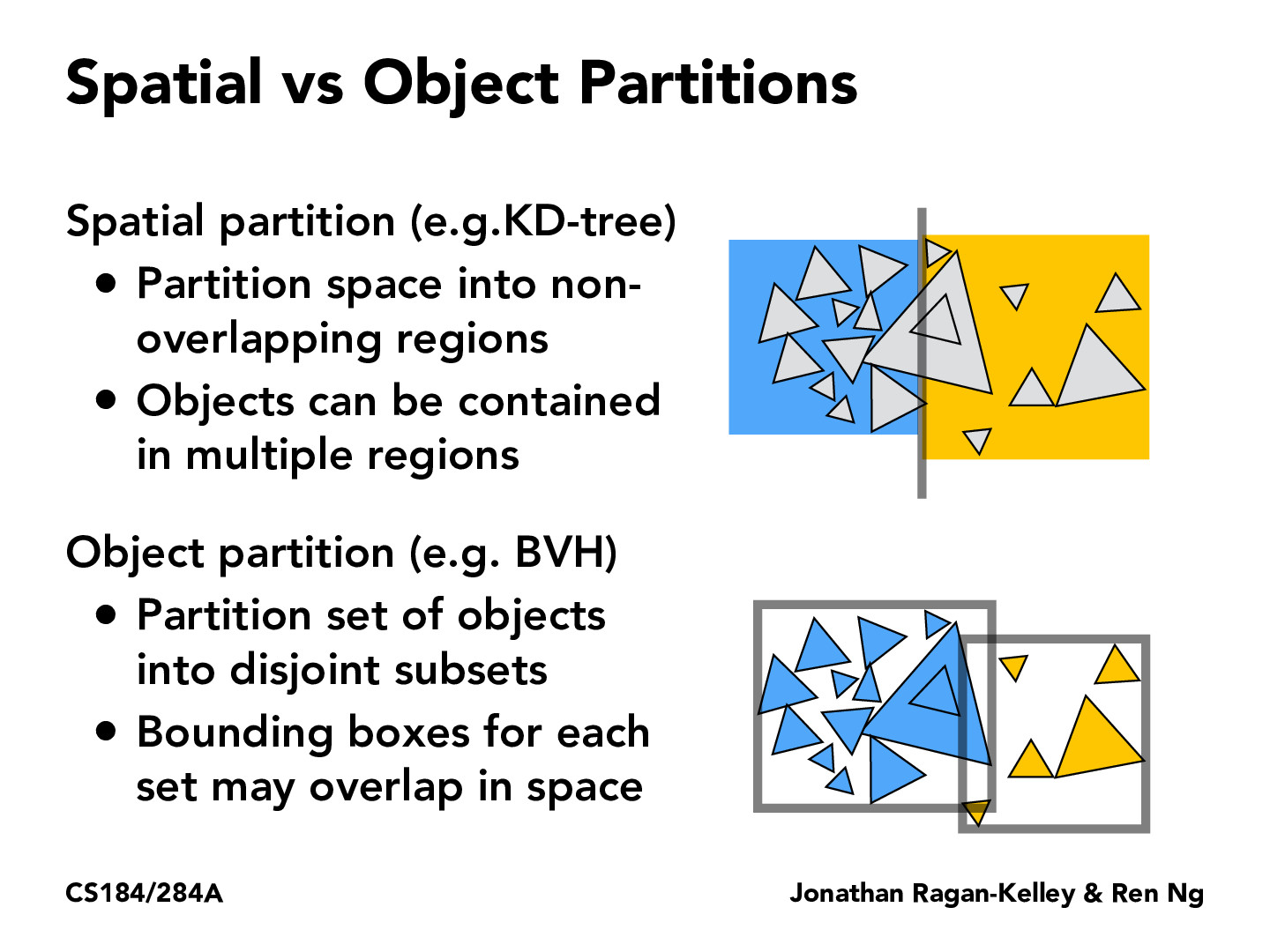
Is there any benefit for using one over the other? Is there a particular algorithm that is used in practice more often than the other?
For partitions, is there any existing methods that use clustering techniques, such as k-means clustering or DBSCAN? If so, what is the pros and cons of clustering-based partitions as compared to say spatial or object partitions?
In the example given, what happens when one of the triangles (e.g. the big blue one in the left bounding box) is technically contained in the two object partitions? I assume that it will only be counted for once in the box that fully contains it, and ignored in the other, but does the second bounding box test to tell if it contains the object fully when deciding if it stores it? Or is the bounding box created after you decide which triangles belong in which bounding box?
To sunsarah: I think that if one of the triangles is "contained" in two object partitions, then it's only counted in the one that fully contains it. The first bullet point under "Object partition" says that the set of objects are "disjoint subsets" so each object would only belong to one partition.
Also to sunsarah: I think that the bounding box is created after deciding which triangles belong in which bounding box, based on slides 71 https://cs184.eecs.berkeley.edu/sp19/lecture/9-71/raytracing and 72 https://cs184.eecs.berkeley.edu/sp19/lecture/9-72/raytracing. In preprocessing we define the bounding boxes, recursively split into two subsets, and continue until the termination criteria. Also I think the bounding box is just an identification variable under each node (slide 71). The bounding box wouldn't track objects that are not fully contained within it, especially because the sets are disjoint, so all objects "inside" a bounding box are considered to be fully inside of it, and partially contained objects are disregarded. (I hope this is correct)
This paper goes into a technical analysis and comparison of various ways to apply spatial partitioning in large-scale, real-time crowd simulations if anyone is interested in a real-world application and a more detailed look into tradeoffs of different data structures: https://dspace5.zcu.cz/bitstream/11025/10652/1/Li.pdf (Page 4 has some cool visualizations of how it actually works on different sized data sets)