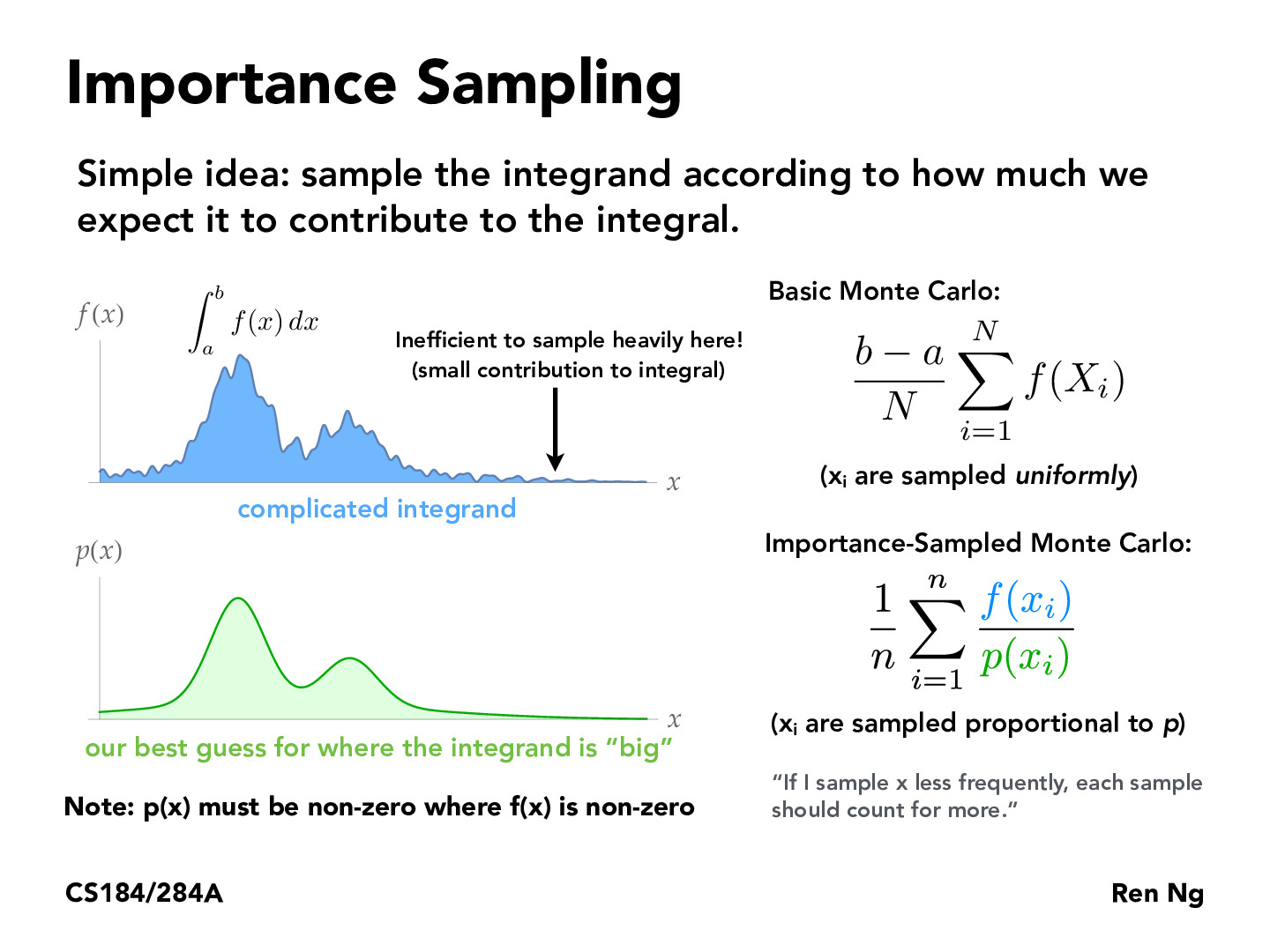
To clarify, this method not only selects the best places to sample based off potential impact, but weighs each sample depending on the amount that sample represents?
arjunsrinivasan1997
What function do we use to choose which points we think will contribute more to the integral?
afang-story
The function we use depends on the assumptions made. In the slide, f is the function we are trying to estimate and can sample from, while p is our assumption of what f is like.
jsc723
I think if we don't know f(x), we can first sample some points in f and get some idea of its shape, and then come up with a p(x) that can find the integral efficiently.
eliot1019
How do we come up with p(x)? Do we sample f(x) to get some kind of rough estimate?
youtuyy
So we don't know f(x) and we want to find out the distribution similar to it, which is p(x)? And we find p(x) by sampling some points in f and see how much they contribute to the integral and decide on the distribution of p? How much sampling of f(x) do we need here?
moridin22
One option is if you have some specific knowledge about the behavior of f, you can incorporate that into your sampling pdf. For example, when trying to estimate direct lighting, you can sample only over the light sources instead of doing uniform hemisphere sampling, since we know that the light sources will provide the only nonzero contributions to the integral.
raghav-cs184
Not sure why p(x) must be non-zero where f(x) is non-zero? Purely analytically this seems permissible? The probability of picking an f where you would have to divide by 0 is 0, and so you would never have to divide by 0. Also as far as I can tell, the best estimator calculations still hold because the probabilities will still cancel out on the region near where it is 0 in the limit?
fywu85
If p(x) is zero, then the point will never get sampled and hence never appear in the importance-sampled MC summation. Therefore, it seems that p(x) is OK to be zero where f(x) is nonzero.
killawhale2
Technically, for points that have zero probability, you can construct a new sample space from the original sample space by excluding all the samples with zero probability. In this case, you can avoid p(x) being zero for any sequence of sampled x_i's.
chenwnicole
Is importance-sampled MC basically the general MC?
To clarify, this method not only selects the best places to sample based off potential impact, but weighs each sample depending on the amount that sample represents?
What function do we use to choose which points we think will contribute more to the integral?
The function we use depends on the assumptions made. In the slide, f is the function we are trying to estimate and can sample from, while p is our assumption of what f is like.
I think if we don't know f(x), we can first sample some points in f and get some idea of its shape, and then come up with a p(x) that can find the integral efficiently.
How do we come up with p(x)? Do we sample f(x) to get some kind of rough estimate?
So we don't know f(x) and we want to find out the distribution similar to it, which is p(x)? And we find p(x) by sampling some points in f and see how much they contribute to the integral and decide on the distribution of p? How much sampling of f(x) do we need here?
One option is if you have some specific knowledge about the behavior of f, you can incorporate that into your sampling pdf. For example, when trying to estimate direct lighting, you can sample only over the light sources instead of doing uniform hemisphere sampling, since we know that the light sources will provide the only nonzero contributions to the integral.
Not sure why p(x) must be non-zero where f(x) is non-zero? Purely analytically this seems permissible? The probability of picking an f where you would have to divide by 0 is 0, and so you would never have to divide by 0. Also as far as I can tell, the best estimator calculations still hold because the probabilities will still cancel out on the region near where it is 0 in the limit?
If p(x) is zero, then the point will never get sampled and hence never appear in the importance-sampled MC summation. Therefore, it seems that p(x) is OK to be zero where f(x) is nonzero.
Technically, for points that have zero probability, you can construct a new sample space from the original sample space by excluding all the samples with zero probability. In this case, you can avoid p(x) being zero for any sequence of sampled x_i's.
Is importance-sampled MC basically the general MC?