If we consider our triangle as the domain of a bi-variable function, this method of sampling looks like that of the Riemann sum for calculating the numeric integral of the function. Some interesting better sampling strategies exists if we know more about the function as in numeric integration.
anthonyhsyu
I remember in math classes back in grade school when we estimated areas of objects, we counted unit squares the object enclosed, but we also followed a schema that checked roughly how much of the square was covered (i.e. if it is more than half-filled, count the square as a whole). Why is it when we sample here we just take the pixel centers? Is it simply because this is easier to get than finding how much of the pixel is covered? Wondering since this avoids the awkward issue of that lone pixel filled in the bottom left.
Staffviviehn
@anthonyhsyu -- What you're suggesting is essentially what we do when super sampling! In the rasterization paradigm, it's not efficient to analytically compute how much of the pixel is "covered" by the triangle
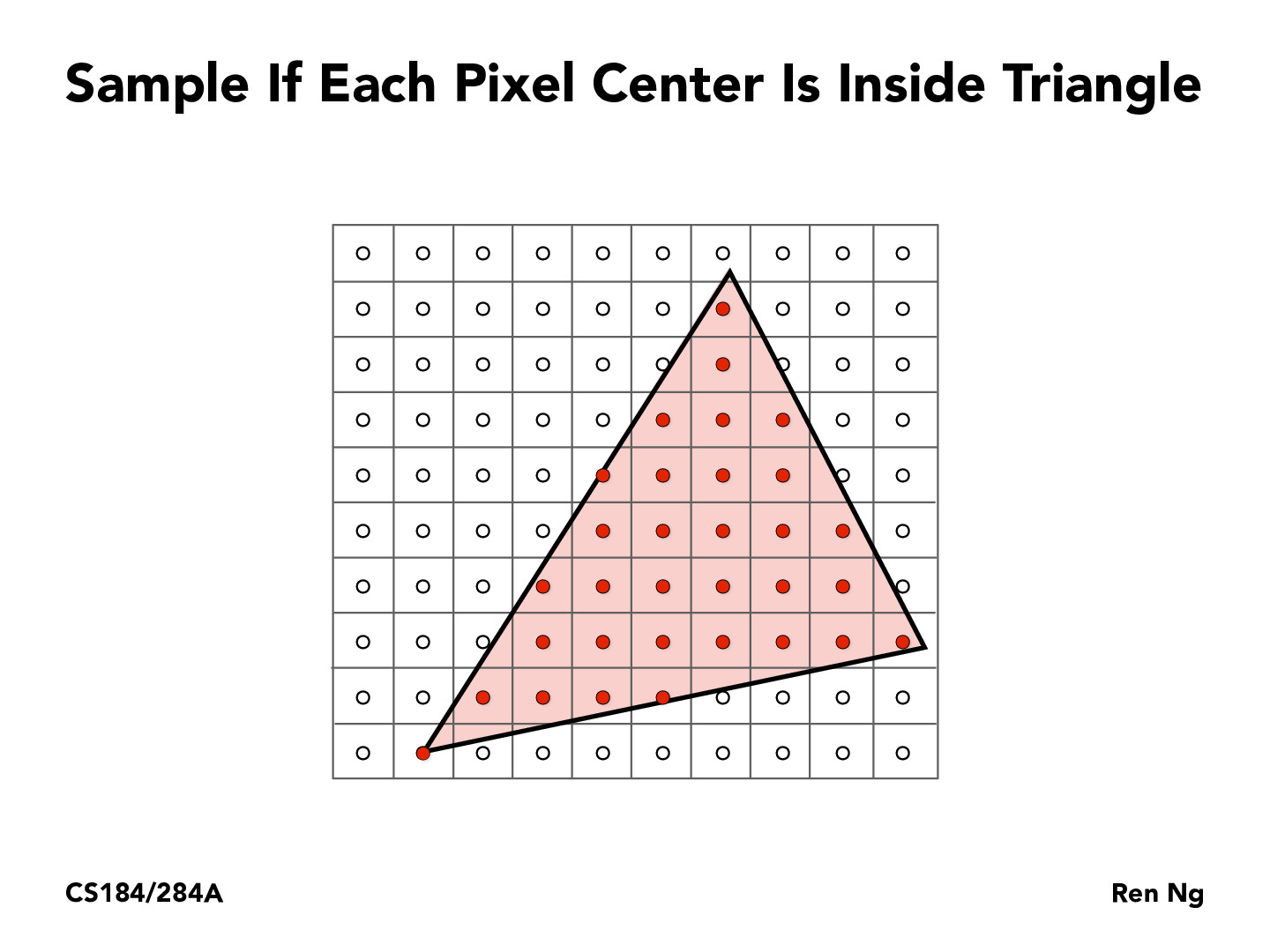
If we consider our triangle as the domain of a bi-variable function, this method of sampling looks like that of the Riemann sum for calculating the numeric integral of the function. Some interesting better sampling strategies exists if we know more about the function as in numeric integration.
I remember in math classes back in grade school when we estimated areas of objects, we counted unit squares the object enclosed, but we also followed a schema that checked roughly how much of the square was covered (i.e. if it is more than half-filled, count the square as a whole). Why is it when we sample here we just take the pixel centers? Is it simply because this is easier to get than finding how much of the pixel is covered? Wondering since this avoids the awkward issue of that lone pixel filled in the bottom left.
@anthonyhsyu -- What you're suggesting is essentially what we do when super sampling! In the rasterization paradigm, it's not efficient to analytically compute how much of the pixel is "covered" by the triangle